-
BERT 논문 리뷰Internship_LLM 2024. 1. 9. 14:43728x90
지난 시간에 Attention Is All You Need를 통해서 Transformer 논문을 리뷰해보았다.
이번 시간에는 Transformer를 활용한 BERT 모델 논문을 리뷰해보고자 한다.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
Google AI의 BERT 논문이며, 당대 GPT-1을 뛰어넘는 SOTA를 달성한 논문이다.
※ BERT란?
모든 layers 에서 left and right context의 공동 조건화에 의한 unlabeled text로부터 deep bidirectional representation을 pre-trained 하도록 설계된 모델
- pre-trained 된 BERT 모델은 just one additional output layer 만으로 fine-tuned 할 수 있고, 구체적인 아키텍쳐를 크게 수정하지 않고도 wide range의 task에 SOTA를 달성하게 된다.
1. INTRODUCTION
- LM의 pre-training은 NLP task에서 굉장히 효과적이다. 특히, 문장을 총체적으로 분석해서 관계를 예측하는 NLI와 paraphrasing 과 같은 <sentence-level task>, named entity recognition과 question answering을 의미하는 <token-level task>에서 효과적이다.
- pre-trained language representations를 down stream task에 적용시키기 위한 데에는 크게 두 가지의 전략이 있다.
1) Feature - based 전략 : ELMo와 같이 사전 학습된 표현을 추가 기능으로 포함하는 task-specific 아키텍쳐를 사용하는 것.
2) Fine-tuning 방식 : OpenAI GPT가 대표적인 예시이며, minimal task-specific parameter를 도입하거나, 모든 사전 학습된 파라미터를 fine-tuning 하여 down stream에 대해 학습하는 방식
- Fine-tuning 방식은 pre-trained representation의 power를 떨어뜨린다.
ex) GPT : 단 방향 모델이라 pre-training 동안 사용할 수 있는 아키텍쳐의 선택이 제한적이다. 왼->오 아키텍쳐를 사용하며 모든 토큰이 이전 토큰과의 Attention만 계산하게 되는 방식으로 문장 수준 task에는 최적이 아니다. token-level task(질문 답변)과 같은 경우는 Fine-tuning 접근 방식 적용시에 더 해로울 수 있다.
- Masked LM을 pre-training의 목적으로 사용하여 단 방향의 제약을 완화시키는 BERT를 제안함으로써 fine-tuning based 접근법을 향상시킨다.
- Masked LM : input 토큰의 일부를 랜덤하게 masking 시키고, 해당 토큰이 구성하는 context를 기반으로, 마스킹 된 토큰의 원래 단어 id를 정확히 예측하는 것을 목표로 한다.
-> 단방향(왼->오) 언어 모델 사전 학습과는 달리 양방향 context를 융합시켜 deep bidirectional Transformer를 가능하게 한다.
-> text-pair representations를 사전 학습 시키면 Next sentence prediction이 가능해진다.
2. Related Work
2.1 Unsupervised Feature-based Approaches
- pre-trained word embedding은 처음부터 학습된 embedding 보다 성능이 향상됨.
- Pre-train word embedding vector : left -> right를 나열하는 것이 목표, left와 right context에서 correct, incorrect words를 구분하는 것이 목표.
- sentence embedding vs paragraph embedding으로 구분된다.
<BERT 이전 연구>
1) rank candidiate next sentence가 목표
2) 이전 문장 표현이 주어지면 다음 문장 단어를 left to right로 생성하는 것이 목표
3) 노이즈를 제거한 Auto-encoder에서 파생한 것이 목표
<ELMo와 후속 모델들>
1) 전통적인 word embedding을 다른 차원으로 일반화함.
2) left to right, right to left 된 언어 모델에서 context-sensitive한 feature를 추출한다.
3) 각 토큰의 contextual representation은 left to right, right to left 표현을 concatenate한 Shallow bidirectional 이다.
- Contextual word embedding을 task-specific 아키텍쳐와 통합할 경우 ELMo는 질의 응답, 감정 분석, 명명된 개체 인식 등에서 SOTA 수준으로 올라가게 된다.
<LSTM>
- left to right 문맥에서 하나의 단어를 예측하는 task를 통해 문맥 표현을 학습하는 것을 제안 => ELMo처럼 Feauture-based이고, 양방향성이 deep하지는 않다.
2.2 Unsupervised Fine-tuning Approaches
- unlabeld text 로부터 word embedding parameters를 pre-training 하는 방향으로 진행된다.
최근에 contextual token representations를 만들어내는 문장 or 문서 encoder가 supervised down stream task를 위해서 unlabeled text와 fine-tuned 로부터 pre-trained 되었다.
-> Scratch에 적은 parameter로도 충분하다는 장점 : OpenAI GPT가 이러한 이점을 통해 GLUE에서 SOTA를 달성하게 된다.
2.3 Trnasfer Learning from Supervised Data
- 자연어처리, CV 등에서 large pre-trained models를 이용해 transfer learning을 하는 중요성이 높아지고 있다.
CV : ImageNet을 이용해서 pre-trained 모델을 fine-tuning 한 모델의 성능이 좋다.
3. BERT
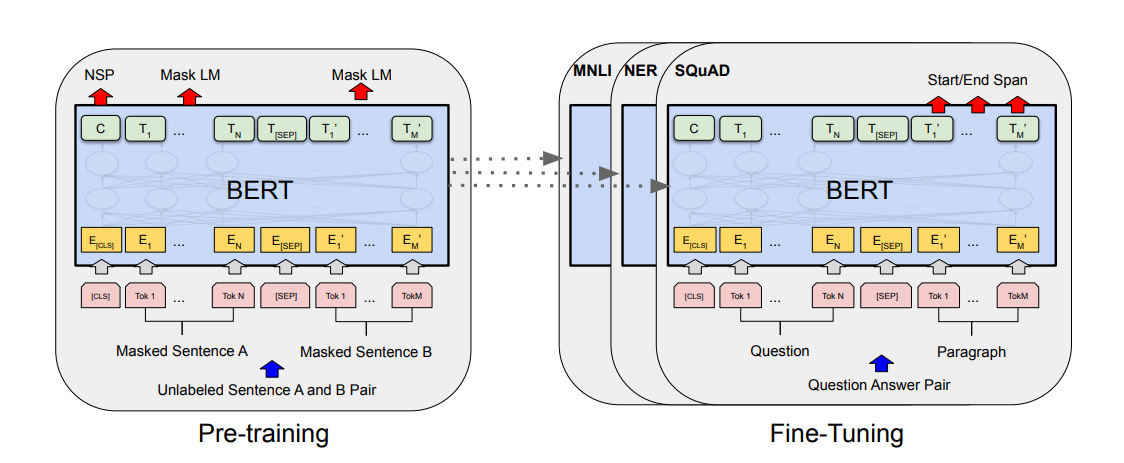
1) Pre-training : 모델은 pre-training task를 통해 unlabeled data를 학습하게 된다.
2) Fine-tuning
㉮ pre-trained 파라미터를 통해 BERT 모델을 초기화시킨다.
㉯ down stream 작업의 labeled data를 사용해서 모든 파라미터를 fine-tuned 시킨다.
(각 down stream에는 초기화되어 있더라도 별도로 fine-tuning 된 모델이 있다.)
=> 동일한 Pre-trained model의 파라미터가 서로 다른 down stream task의 초깃값으로 사용된다 : 초깃값들은 fine-tuning 과정에서 down stream task에 맞게 조정된다.
<Model Architecture>
1. BERT base (L=12, H=768, A=12) 총 110M개의 파라미터 = GPT와의 성능 비교를 위해 파라미터 수를 동일하게 설정.
2. BERT large (L=24, H=1024, A=16) 총 340M개의 파라미터
=> GPT는 모든 토큰이 왼쪽 토큰들과만 Attention을 계산하는 Constrained Self-Attention이다.
=> BERT는 Bidirectional Self-Attention
<Input/Output Representations>
1) BERT가 다양한 down stream tasks에 잘 적용되기 위해서는 Input representation이 Single sentence와 A pair of sentence(Q&A)에 애매하지 않게 표현되어야 한다.
-> "Sentence"는 실제 언어 문장이 아니라, 연속된 텍스트의 임의의 범위를 뜻한다.
-> "Sequence"는 BERT에 입력된 토큰 시퀀스, 하나의 문장 or 두 개의 문장이 묶인 형태이다.
2) 총 3만개의 토큰 어휘를 포함하는 Word Piece 임베딩을 사용
3) 모든 시퀀스의 첫 번째 토큰은 special classification token(CLS)
4) Final hidden state는 Classification 작업을 위한 Aggregate Sequence
5) 문장 쌍은 하나의 시퀀스로 묶임
6) 두 가지 방법으로 문장을 구분한다.
- Special token(SEP)로 구분
- 모든 토큰에 학습된 임베딩을 추가하여 해당 토큰이 문장 A에 속하는지 문장 B에 속하는지를 나타낸다.(Segment Embedding)
Input Representation = Segment Embedding + Token Embedding + Position Embedding
(Token Embedding : WordPiece embedding, Position Embedding : Transformer와 동일)
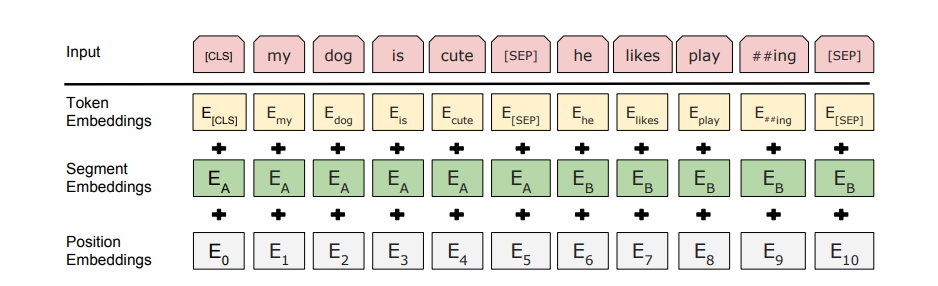
3.1 Pre-training BERT
- 이전의 전통적인 left to right, right to left 언어 모델을 사용하지 않음. 대신에 두 가지의 unsupervised-task를 사용한다.
#1. MLM(Masked LM)
- 직관적으로도 deep bidirectional model이 left to right나 Shallow concatenation(left to right, right to left) 보다 성능이 좋다.
- Standard conditional language model : left to right, right to left의 학습만 가능했음
- Bidirectional conditiong은 각 단어가 "See itself" 할 수 있도록 하여 모델이 multi-layer context에서 target word 예측이 가능하다.
■ MLM 방식 : deep bidirectional representation을 훈련시키기 위해서 input token을 random하게 일정 비율을 masking 하여 masked token을 predict 하면 된다. => "cloze task"라고도 부른다.
- 마스크 토큰의 final hidden vector는 Standard LM에서와 마찬가지로 vocabulary에 대한 output softmax에 공급됨.
- 15%를 무작위로 masking 했다.
- Only predict the masked words
단점 : fine-tuning 동안 토큰이 나타나지 않아 pre-trained model과 fine-tuning 간에 mismatch가 발생한다.
-> 해결책
1) "masked" words를 항상 실제 [MASK] 토큰으로 대체하지는 않는다.
2) 토큰 위치의 15%를 학습 데이터 생성기가 무작위로 선택
- 80% : token을 [MASK] token으로 대체
- 10% : token을 random token으로 대체(15% 중 10%라 총 1.5%) -> 모델의 언어 이해 능력에 해를 끼치지는 않는다.
- 10% : unchanged
∴ 이렇게 해서 T_i가 original token을 cross entropy loss를 통해 predict하게 된다.
- 이 절차를 통해서 Transformer encoder가 어떤 단어를 예측해야 하는지, 어떤 단어가 random한 단어로 대체되었는지 알 수 없기 때문에 입력 토큰의 distributional contextual representation을 유지해야 한다.
- Masked LM은 각 배치에서 토큰의 15%에 대해서만 예측을 수행하기 때문에 모델에 더 많은 pre-trained 단계가 필요할 수 있다.
#2. NSP(Next Sentence Prediction)
1) QA(Question Answering)이나 NLI는 언어 모델링으로 제대로 포착되지 않는 두 문장 간의 relationship을 이해하는 것이 핵심이다.
2) 문장 간 관계 이해를 위해서 "next sentence prediction" task를 pre-train 했다.
3) 사전 학습 예제에서 문장 A와 B를 선택할 때
- 50% : B가 A 다음에 오는 실제 다음 문장
- 50% : corpus에서 무작위로 생성된 문장
<Pre-training Procedure>
문장은 결합된 길이가 512토큰 이하가 되도록 샘플링 되며, LM 마스킹은 WordPiece tokenization 후에 15%의 단일 형태 마스킹 비율로 적용된다. 또한, 부분 단어 조각에 대해서는 특별히 고려하지 않는다.
=> 위 그림에서 초록색 표시 부분에 C를 찾을 수 있는데, 이 C가 NSP를 위한 토큰이다. 이 토큰을 이용해서 위의 50%를 각각 처리하게 된다.
4) BERT는 모든 파라미터를 전송하여 end-task model parameter를 초기화시킨다. -> 이전에는 문장 embedding만 down stream task로 전송되었었다.
<Pre-training data>
document-level corpus가 shuffled sentence-level corpus보다 연속된 긴 sequences를 출력하기 위해서는 훨씬 유리하다.
3.2 Fine-tuning BERT
- Transformer의 Self-Attention 매커니즘 덕분에 BERT는 간단한 Fine-tuning으로 많은 down stream task가 가능해진다.
일반적으로 text paris application의 경우, bidirectional Cross-Attention을 적용하기 전에, text pairs를 독립적으로 encoding 해줘야 한다. 하지만, 이 부분을 BERT는 Self-Attention mechanism을 사용해서 두 단계를 통합해버린다.
Self-Attention으로 합쳐진 text pairs를 인코딩하면 bidirectional cross attention이 효과적으로 포함될 수 있기 때문에 두 단계를 통합적으로 운영할 수 있게 된다.
- 각 task 마다 task의 구체적인 input과 output을 BERT에 입력하고, 모든 문장을 end to end로 fine-tune 했다.
1) sentence pairs in paraphrasing
2) hypothesis-premise pairs in entailment
3) Question-passage pairs in question answering
4) degenerate text-not pair in text classification or sequence tagging.
- Output도 token-level task를 위한 output layer가 들어가게 된다.
1) sequence tagging or question answering
2) [CLS] representation(entailment, sentiment analysis)
4. Experiment

1) BERT large가 SOTA를 달성(GLUE)
- BERT large의 경우, 작은 데이터셋에서 fine-tuning이 unstable 하여, 여러번 무작위로 restart하고 개발 세트에서 적합한 모델을 선택한다.
- 훈련 데이터가 적은 작업에도 BERT large가 BERT base를 크게 능가한다.

SQuAD 1.1 results 
SquAD 2.0 results 
SWAG results 2) (SQuAD, SWAG)에서도 SOTA를 달성
- SQuAD : 질문과 지문을 주고, 정답을 맞히는 task
- SWAG : 앞 문장이 주어지고, 보기가 주어지는 것 중 잘 이어지는 문장을 찾는 task
-> SWAG는 113k sentence-pair completion, grounded common-sense inference를 평가하기 위한 task이다.
5. Ablation Studies
5.1 Effect of Pre-training Tasks

1) No NSP : MLM은 사용하지만, NSP는 수행하지 않는 bidirectional model
2) LTR & No NSP : left context only model. MLM이 아닌 Standard (LTR) LM을 사용해서 학습. left context only model 조건을 제거하면 down stream 성능이 저하(pre-train / fine-tune mismatch)가 발생하므로, fine-tuning 시에도 이를 적용시켜준다.
3) NSP 작업 없이 pre-trained
4) GPT와 직접적으로 비교될 수 있는데, Large training data set과 input representation과 fine-tuning 체계를 사용했다.
5) Pre-training task를 하나라도 제거하면 성능이 감소한다.
6) No NSP : NLI 계열의 task는 성능이 감소한다.(NSP가 문장 간 논리 구조에 중요한 역할을 한다는 점)
7) MLM 대신 LTR 쓰면 성능이 더욱 하락한다.( + BiLSTM 역시 성능이 하락한다.) -> MLM task가 더 Deep bidirectional!!!!
5.2 Effect of Model Size

Ablation over BERT model size 1) 모든 4개의 dataset에서 Larger models가 accuracy 향상을 이끌어냈음.
-> Large dataset은 반드시 성능 향상을 불러온다!!!!
but, 모델이 충분히 pre-trained 되었다면 극단적 모델 크기로도 small scale task에서도 large improvement를 이끌어낼 수 있다.
2) 선행 연구들이 feature-based approach를 사용했는데, BERT는 모델을 down stream 작업에서 fine-tuning 하고 아주 적은 수의 randomly initialized additional parameters를 사용하면, down stream task data가 매우 작더라도 모델이 더 크고 뛰어난 pre-trained 표현의 이점을 누릴 수 있다는 가설을 세웠다.
5.3 Feature-based Approach with BERT

CoNLL-2003 Named Entity Recognition results BERT의 모든 결과는 pre-trained 모델에 간단한 classification 계층을 추가하고, 모든 파라미터를 down stream에서 fine-tuning 하는 Fine-tuning Approach를 사용했다.
However, pre-trained 모델에서 fixed feature를 추출하는 Feature-based Approach도 몇 가지의 장점이 있다.
1) 모든 task가 Transformer encoder 아키텍쳐로 쉽게 표현되는 것은 아니라, task-specific model 아키텍쳐가 추가되어야 한다.
2) 학습 데이터의 값 비싼 표현을 pre-compute 하고 이 표현 위에 더 저렴한 모델을 실험하게 되면 계산상의 이점이 많다.
6. Conclusion
■ 언어 모델을 사용한 Transfer Learning으로 인한 개선은 Unsupervised pre-training이 언어 이해 시스템의 통합적인 부분임을 증명했다.
-> 이러한 결과를 통해 리소스가 적은 작업도 Deep unidirectional Architecture의 이점을 누릴 수 있게 되었다.
■ Deep bidirectional Architecture로 일반화하여 동일한 pre-trained model이 광범위한 NLP 작업을 성공적으로 처리하는 것에 BERT가 공헌했다.
※ Comparison of BERT, ELMo, and OpenAI GPT

1. pre-training model architecture의 차이점
- BERT : 양방향 트랜스포머(모든 layer에서 왼쪽과 오른쪽 context 모두에 대해 jointly conditioned 된다.), fine-tuning
- GPT : 왼 -> 오 트랜스포머, fine-tuning
- ELMo : 독립적으로 훈련된 왼 -> 오, 오-> 왼 LSTM의 연결을 사용하여 down stream 작업을 위한 feature를 생성, feature-based approach
2. BERT와 가장 유사한 기존 pre-train 방법은 큰 text corpus에 대해서 left to right으로 Transformer LM을 훈련하는 GPT이다. BERT는 GPT에 의도적으로 최대한 가깝게 만들어졌는데, 이는 두 방법을 비교하기 위해서이다.
3. GPT는 BooksCorpus(8억 단어) 학습, BERT는 BooksCorpus(8억 단어)와 위키피디아(2500억 단어)를 학습.
4. GPT는 fine-tuning 시에만 도입되는 separator([SEP])와 classifier token([CLS])를 사용했고, BERT는 pre-train 중에 [SEP], [CLS] 그리고 문장 A/B 임베딩을 학습한다.
5. GPT는 32,000단어 배치 크기로 1M step을 학습했고, BERT는 128,000단어 배치 크기로 1M step을 학습했다.
6. GPT는 모든 fine-tuning 실험에 동일한 learning rate=5e-5를 사용했지만, BERT는 개발 세트에서 가장 우수한 성능을 발휘하는 fine-tuning learning rate를 선택한다.
※ BERT를 이용한 문제 Fine-tuning과 사용된 Datasets
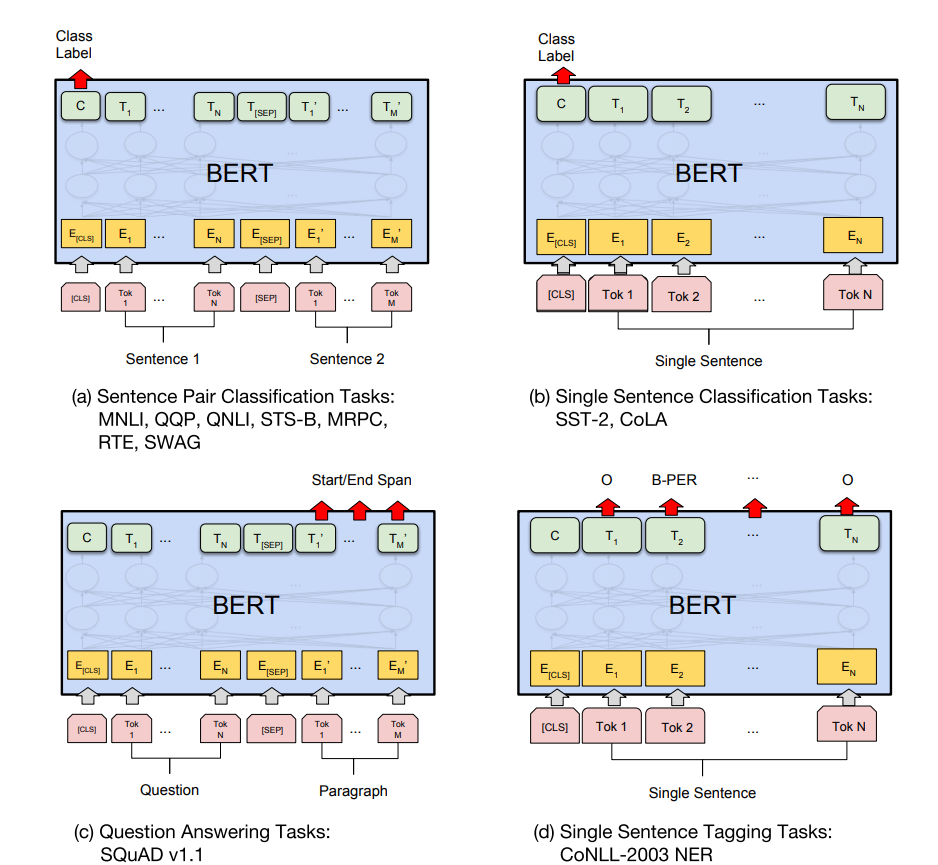
(a), (b)는 시퀀스 수준 태스크, (c), (d)는 토큰 수준 태스크
E : 입력 임베딩
T_i : 토큰 i의 context 표현
[CLS] : Classification 출력
[SEP] : 연속되지 않은 토큰 시퀀스를 구분하기 위한 특수 기호
MNLI : 다중 장르 NLI는 large-scale의 crowdsourced 기반 분류 작업. 한 쌍의 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장과 관련하여 entailment, contradiction, neutral인지를 예측하는 것이 목표.
QQP : Quora Question Pairs는 이진 분류 작업으로, 질문한 두개의 질문이 의미적으로 동등한지 판단하는 것이 목표.
QNLI : Question Natural Language Inference는 Stanford Question Answering Dataset을 이진 분류 작업으로 전환한 버전. 긍정적인 예는 정답을 포함하는 (질문, 문장)쌍이고, 부정적인 예는 정답을 포함하지 않는 같은 paragraph의 (질문, 문장)쌍이다.
SST-2 : Stanford Sentiment Treebank는 영화 리뷰에서 추출한 문장과 그 감정에 대한 사람의 주석으로 구성된 이진 단문 분류 작업
CoLA : Corpus of Linuistir Acceptability는 영어 문장이 언어적으로 "acceptable" 한지 여부를 예측하는 것이 목표인 이진 단일 문장 분류 작업.
STS-B : Semantic Textual Similarity Benchmark는 뉴스 헤드라인 및 기타 출처에서 가져온 문장 쌍의 모음.
MRPC : Microsoft Research Paraphrase Corpus는 온라인 뉴스 소스에서 자동으로 추출된 문장 쌍과 사람의 주석으로 구성.
RTE : Recognizing Textual Entailment는 MNLI와 유사하지만 훈련데이터는 훨씬 적은 binary entailment task
WNLI : Winograd NLI는 소규모 natural language inference dataset.

BERT는 MASK, SAME, RND를 각각 80%, 10%, 10% 사용했으며, NER Fine-tune에서 매우 강력하다는 것을 확인할 수 있다.
728x90'Internship_LLM' 카테고리의 다른 글
Instruction finetuning & Self-Instruct (0) 2024.01.26 SELF-INSTRUCT 논문 리뷰 (0) 2024.01.24 GPT - 1.0 논문 리뷰 (0) 2024.01.12 Attention Is All You Need - Transformer 논문 리뷰 (2) 2024.01.04 Attention 초기 논문 리뷰 (3) 2024.01.04