-
Attention Is All You Need - Transformer 논문 리뷰Internship_LLM 2024. 1. 4. 17:23728x90
Attention 초기 논문에 이어 Transformer 모델을 제시한 "Attention Is All You Need" 논문을 리뷰해보고자 한다.
LLM을 위해서 뿐만 아니라 거의 모든 AI에 적용되고 있는 모델들이기에 이 기회에 논문을 정독하고 리뷰를 작성해서 기록해보고자 했다.
1. Introduction
RNN 자체는 재귀적 순환 구조를 가지고 있다보니 긴 Sequence 길이, 메모리의 한계와 같은 문제들에 봉착하게 되었다.
-> 이 문제들을 해결하기 위해 모든 Network Architecture를 Attention 모델만을 이용해서 구축하고자 제안한 모델이 바로 Transformer이다.
-> Attention이 입력, 출력 sequence 거리에 관계없이 종속성 모델링이 가능하다는 점을 이용하여 더 많은 병렬화를 구현하기 위한 목적을 가진다.
2. Background
1) Sequential computation을 줄이는 것은 GPU, ByteNet, ConvS2S에서도 다루고 있다.
-> 주로 CNN을 basic building block으로 다루고 있으며, distant positions 사이에서 학습 dependencies를 더 어렵게 한다는 문제가 있다.
2) Self-Attention : Sequence의 표현 계산을 위해서 single sequence의 서로 다른 위치와 관련이 있다.
-> reading comprehension, abstractive summerization, textual entailment, 독립된 문장의 learning task 등에 효과적으로 사용되었다.
3) End to End memory network : sequence-aligned recurrence 보다 recurrent attention mechanism에 기초한다.
-> 간단한 언어 질문 답변, 언어 모델 task에 좋은 성능을 가진다.
4) Transformer : 입, 출력 계산을 위해 Sequence 정렬 RNN, convolution을 사용하지 않고 전적으로 Self-Attention에 의존한다.
3. Model Architecture
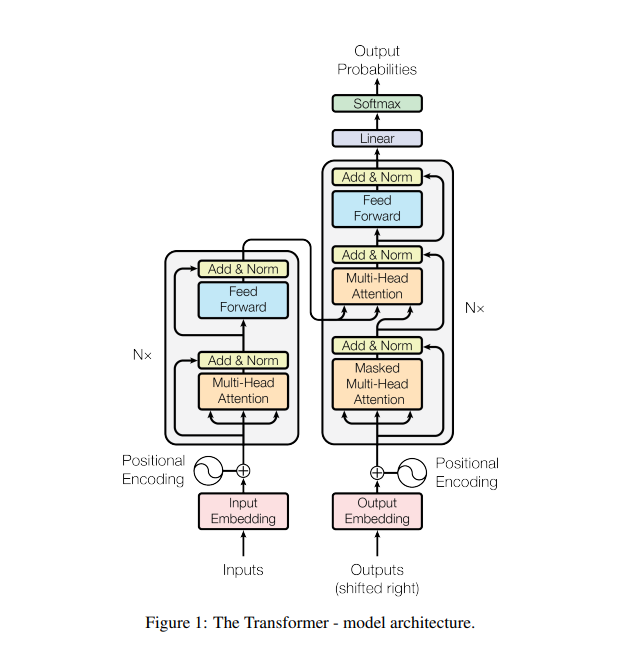
3.1 <Encoder>
1) N=6의 identical layers를 stack으로 쌓음
2) 각 layer는 2개의 sub-layers를 가짐
3) 처음은 multi-head self-attention mechanism
4) 두 번째는 fully-connected feed-forward network
5) two sub layers 마다 layer normalization 후에 residual connection을 사용함.
6) 각 sub-layer의 output은 LayerNorm(x + Sublayer(x))로 계산(Sublayer(x) : sub-layer 자체에서 구현된 함수)
7) 모든 sub-layers, embedding layers들은 d_model = 512 차원의 output을 생산함.
3.1 <Decoder>
1) N=6인 identical layers의 stack으로 쌓음
2) 각 encoder layer에 2개의 sub-layers를 가짐
3) decoder는 인코더 스택 출력에 대해 multi-head attention을 수행하는 3번째 sub-layer를 삽입
4) 각 sub-layer에 layer normalization 후 residual connection을 사용함.
5) decoder stack에 있는 self-attention sub-layer를 수정 -> 위치가 후속 위치에 영향을 받지 않도록 하기 위해서.
6) masking을 통해 i 위치의 prediction이 i보다 이전 위치에 의존하도록 함.
3.2 <Attention>
1) query, key-value 쌍을 output에 mapping(query, key, value, output은 모두 vector)
2) output은 weighted sum으로 계산됨.
3) weight : key와 query의 compatibility function으로 계산됨.
3.2.1 <Scaled Dot-Product Attention>
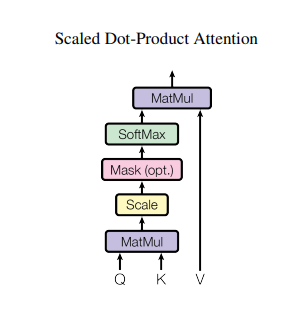
1) Input : dimension d_k의 query와 keys, dimension d_v의 values

2) Additive attention function : 단일 hidden layer에서 feed-forward netowrk를 사용하는 compatibility function으로 계산
3) Dot-Product Attention function : 1/(d_k)^(1/2)의 scaling factor를 제외하면 transformer와 동일한 알고리즘.
4) 더 최적화된 matrix multiplication code를 이용하므로 Dot-Product가 더 빠르고 공간 효율적이다.
5) d_k가 낮을 때 : Additive attention function과 Dot-Product Attention function이 거의 유사
6) Not scaled d_k가 높을 때 : Additive attention function > Dot-Product Attention function
7) d_k가 커지면 Dot-Product가 커져, softmax function이 gradients가 감소하는 문제가 발생 -> 문제 방지를 위해 1/(d_k)^(1/2) 로 스케일링 실시
3.2.2 <Multi-Head Attention>
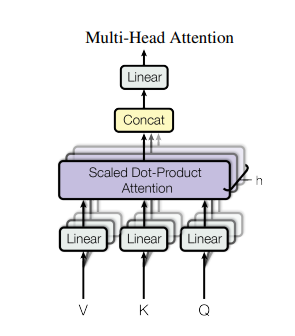
1) Single Attention function에서 d_model - dimensional keys, values, queries를 수행하는 것과, queries, keys, values를 h번 다른, 학습된 linear projections d_k, d_k와 d_v 차원에 linearly하게 project 하는 것을 비교했을 때, 후자가 훨씬 우세하다.
2) queries, keys, values의 projected version이 병렬적으로 Attetion function을 거쳐, d_v-dimensional output value를 만든다.
3) 값을 concatenate하고 다시 projected해서 final values를 얻어낸다.
∴ 각 head 마다 dimension을 줄이기 때문에, total computed cost는 single-head Attention과 유사하게 된다.
3.2.3 <Applications of Attention In Our Model>
Transformer는 multi-head attention을 3가지의 다른 방법으로 사용한다.
1) encoder-decoder Attention layers
ⓐ 이전 decoder의 queries, encoder의 output 으로부터 온 memory key와 values
ⓑ decoder의 모든 위치가 input sequence의 모든 위치를 다룸.
ⓒ Seq2Seq 모델의 전형적인 encoder-decoder Attention mechanism을 모방
2) encoder에는 self-attention layers를 포함한다.
ⓐ encoder의 이전 layer output이 있는 같은 장소에서 self-attention layer의 모든 key, value, queries가 나오게 된다.
ⓑ encoder의 각 위치는 encoder의 이전 layer의 모든 위치를 다룰 수 있다.
3) decoder에도 self-attention layers가 포함된다.
ⓐ decoder의 각 position은 decoder까지 오기 위한 이전 모든 위치를 다룰 수 있다.
ⓑ Auto-regressive property 보존을 위해 decoder에서 leftward information flow를 막아줄 필요가 있다.
ⓒ Scaled Dot-Product Attention의 모든 Softmax input values 중 illegal connection과 일치하는 것들을 -∞로 셋팅하고 masking out한다.
3.3 <Position-wise Feed-Forward Networks>
1) encoder, decoder의 각 layers들은 fully connected feed-forward network를 가진다.
-> 각 position에 separately, identically하게 적용된다.
2) ReLU를 사용, two linear transformation

- linear transformation은 다른 position에 동일, layer to layer에는 다른 parameters를 사용한다.
3.4 <Positional Encoding>
1) recurrence, convolution 사용 X
2) Sequencce의 relative, absolute position에 관한 정보를 주입해야함.

- Pos : Position
- i : dimension
3) 각 positional encoding의 차원의 sin 곡선과 같은 정현파 곡선과 일치한다.
-> 어떤 fixed offset k에서라도 PE_pos+k가 PE_pos의 linear function으로 대표될 수 있기 때문에 위 함수를 사용하며, model이 더 긴 Sequence 추정이 가능하므로 sin 곡선을 사용하는 것이다.
4. Why Self-Attention
Self-Attention vs Recurrent, convolutional Layers
1) Layer 당 total computational complexity
n : sequence 길이, d: dimension
계산복잡도 : n<d의 경우(대부분의 machine translation) Self-Attention이 더 우세함.
2) Sequential parallelize 할 수 있는 계산량
3) long-range dependencies 할 수 있는 계산량
- 많은 sequence transduction tasks의 주요 과제
- 네트워크 순회 시 forward와 backward 신호의 path 길이가 dependencies 학습의 주요 요인이다.

∴ path 길이(input과 output sequences)가 짧을수록 long-range dependencies를 학습하기가 쉽다. -> Input과 Output Path 길이를 비교하자!!!!
∴ 긴 sequence 성능 개선을 위해 neighborhood size를 r로 제한 -> maximum path length = O(n/r)로 증가
∴ k<n인 single convolutional layer with kernel은 모든 쌍의 input과 output 위치를 연결하지 못한다.
- contiguous kernel : O(n/k)
- dilated convolution : O(log_k(n))
∴ Convolution layer가 recurrent layers 보다 일반적으로 더 expensive 함
-> Seperable Convolution의 경우 O(knd + n^d)으로 줄이기 가능. but, k=n은 seperable convolution에서 Self-Attention layer와 point-wise feed forward layer의 조합과 complexity가 동일하다.
∴ Self-Attention은 더 interpretable 한 모델 산출이 가능하다.
∴ Attention head가 다양한 task를 수행할 수 있으며, 문장의 구문적, 의미적 구조를 잘 연관시키게 된다.
Conclusion & Furthermore
- Transformer는 WMT 2014 English-to-German translation, English-to-French translation 에서 SOTA 급의 성능을 모두 보여주었으며, 현재는 language model 뿐만 아니라, Computer Vision 등 모든 AI 분야에서 Transformer를 활용하고 있다. Vision Transformer와 같은 논문들도 기회가 된다면 리뷰해보고 싶다.
논문을 리뷰하고 추가적으로 구체적인 Transformer 모델의 encoder와 decoder의 흐름을 알고 싶다는 생각으로 검색을 하던 중 너무나 잘 정리가 된 포스팅이 있어, 블로그의 링크를 덧붙여 놓으려고 한다.
Drawing the Transformer Network from Scratch (Part 1) | by Thomas Kurbiel | Towards Data Science
[밑시딥] Transformer 동작과정을 밑바닥부터 뜯어보자! (tistory.com)
논문 구현은 [NLP 논문 구현] pytorch로 구현하는 Transformer (Attention is All You Need) – Hansu Kim (cpm0722.github.io) 이 링크를 통해서 많은 도움을 받게 되었다.
728x90'Internship_LLM' 카테고리의 다른 글
Instruction finetuning & Self-Instruct (0) 2024.01.26 SELF-INSTRUCT 논문 리뷰 (0) 2024.01.24 GPT - 1.0 논문 리뷰 (0) 2024.01.12 BERT 논문 리뷰 (0) 2024.01.09 Attention 초기 논문 리뷰 (3) 2024.01.04