-
GPT - 1.0 논문 리뷰Internship_LLM 2024. 1. 12. 17:40728x90
지난 시간에는 BERT 논문을 리뷰해보았는데, 오늘은 BERT와 정확히 반대로 decoder를 건드린 GPT 논문을 리뷰해보려고 한다.
최근 OpenAI의 ChatGPT가 너무나 뛰어난 성능을 보여주면서, BERT를 잘 사용하지 않는 지경에 이르렀고 NLP가 chatGPT로 대통합되는 느낌을 받고 있는데, 그 시초가 되는 논문을 리뷰해보려고 한다.
language_understanding_paper.pdf (openai.com)
Abstract
일반적인 자연어 이해는 textual entailment, QA, sematic similarity assessment, Text Classification 등의 다양한 범위의 task로 구성이 된다. 하지만, large unlabeled text corpora는 풍부하지만, 특별한 tasks를 학습하기 위한 labeled data는 부족한 실정이다. 그로써 차별적으로 trained 된 모델이 좋은 성능을 내기가 쉽지 않다고 논문은 말하고 있다.
GPT??
unlabeled text의 다양한 corpus에 언어 모델을 generative pre-training 한 다음 특정 task에 discriminative fine-tuning 하는 작업을 통해 큰 이득을 얻을 수 있음을 증명한 모델.
-> 이전 접근 방식과는 달리, fine-tuning 중에 task-aware input transform을 통해 모델 아키텍쳐를 최소한으로 변경하면서 효과적인 transfer를 수행한다.
-> 12개의 연구 중 9개 연구에서 SOTA를 기록한다.
Inroduction
NLP 에서는 지도학습 의존도를 낮추기 위해 raw text에서 효과적으로 학습할 수 있는 능력이 중요하다. 하지만, 대부분의 딥러닝에서는 상당량의 수동 labeled data가 필요하므로, 주석이 달린 리소스가 부족한 많은 도메인에서 적용이 제한적이게 된다. 이 상황에서 unsupervised fashion으로 좋은 표현을 학습하는 것은 성능 향상에 많은 도움이 되고 있다.
But, unlabeled text에서 단어 수준 이상의 정보를 활용하는 것은 아래 2가지 이유로 인해 힘든 실정이다.
1) 어떤 유형의 최적화 목표가 transfer에 유용한 text 표현을 학습하는데 효과적인지 불분명함.
2) 학습된 표현을 target task로 전송하는 가장 효과적인 방식의 합의가 이루어지지 않았다. -> 여기서 "가장 효과적인 방식의 합의가 이루어지지 않았다." 는 것은 pretrained model을 fine-tuning 하는데 뭐가 효과적인지를 모른다는 뜻이다.
이러한 불확실성!!!! 이 language processing을 위한 Semi-supervised learning 접근법 개발을 어렵게 하고 있다.
이 논문에서는 언어 이해 task에서 semi-supervised approach를 unsupervised pre-training과 supervised fine-tuning의 결합을 사용해서 실시하고자 한다. 논문에 따르면 모든 task에 보편적인 표현을 학습하고 pre-trained model의 아키텍쳐를 최소한의 변화로 효과적으로 fine-tune 하여 task-specific에 맞게 utilize 하는 것을 목표로 한다고 한다.
네트워크는 Transformer 구조를 사용하며, 12개 tasks 중 9개에서 SOTA를 기록했다. 또한, 4가지 설정에서 pre-trained model의 zero-shot 동작을 분석하여 down stream tasks에 유용한 언어 지식을 습득한다.
Related Work
※ Semi-supervised Learning for NLP
- 지금까지는 unlabeled data로 단어 수준, 구문 수준 통계를 계산한 다음 이를 feature로 사용했다. 이 접근 방식이 단어 수준의 정보를 전송하는 반면 GPT는 더 높은 수준(구, 문장) 등으로 사용하고자 한다.
※ Unsupervised pre-training
- Unsupervised pre-training은 지도학습의 목적을 수정하는 대신, 좋은 초기 표현을 발견하고자 하는 Semi-supervised Learning의 특별한 케이스이다.
- pre-training으로 Deep neural networks를 잘 일반화시켰으며, 최근에는 이것으로 이미지 분류, 음성 인식, 기계번역에 좋은 성능을 내고 있다. 그러나, pre-training은 언어 정보를 capture 하는데 도움을 주지만, LSTM 모델과 같은 usage 모델들의 경우 예측 능력이 short range로 굉장히 제한적이다. 반면에, Transformer는 longer-range 언어 구조를 capture 할 수 있고, 실험적으로 이것이 증명되었다. 이를 통해 자연어 이해, paraphrase detection, story completion 등의 다양한 tasks 들에서 모델이 효과적이라는 것을 증명할 수 있게 된다.
※ Auxiliary traing Objectives
- Semi-supervised Learning의 다른 형태로 NLP 영역에서 POS tagging, chunking, named entity recognition, 언어 모델링 등의 auxiliary NLP tasks에서 다양하게 사용되고 있다.
Framework
훈련 절차는 아래 2가지 Stage를 따른다.
- Stage 1 : 큰 corpus에서의 high-capacity laguage model을 학습하는 것
- Stage 2 : 레이블이 지정되 데이터를 사용한 discriminative 작업에 맞게 모델을 조정하는 fine-tuning 단계
3.1 Unsupervised pre-training

U : {u_1, ..., u_n} : unsupervised corpus of tokens
k : context window의 size
P : theta 파라미터의 신경망을 사용하는 모델로 된 조건부 확률
1) k size context window를 만들기
2) i-1부터 i-k 까지의 단어를 보고, i 번째가 나올 가능성을 최대화하는 방법을 통해 unlabeled data 에서도 학습이 가능한 unsupervised learning을 설계한다.
3) i 번째 text가 나올 확률을 최대화하는 것이라 maximize likelihood 기법을 loss function으로 설정하여 학습한다.
4) SGD(stochastic gradient descent)를 잘 활용해서 parameter train
∴ Unsupervised Learning을 통해서 대용량 text 데이터를 Transformer decoder에 학습 -> Language model로 pre-train
※ 실험에 사용된 조건들
- multi-layer Transformer decoder(LM을 위한) 사용
- input-context token에 multi-headed self-attention을 적용(position-wise feedforward layers를 적용하여 target tokens에 대한 output distribution을 생성한다.)
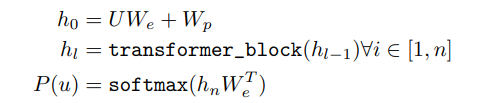
U : context vector of tokens
n : layer 수
W_e : token embedding matrix
W_p : position embedding matrix
∴ Encoder는 vector로 표현되나, Decoder는 distribution으로 표현이 가능하여 token이 어떤 것이 나올지를 예측 가능하다.
3.2 Supervised fine-tuning
모든 구조화된 Input을 token sequences로 변환하여 pre-trained 된 모델에서 처리하고, Linear + softmax layer를 붙여서 fine-tuning 한다.

- labeled dataset C에서 (x_1, ... ,x_m)이라는 y label을 가진 input token의 시퀀스로 구성된다.
- h_l^m : final transforemr block's activation -> input은 pre-trained model을 통과해서 h_l^m을 얻는다.
- y를 예측하는 W_y 파라미터로 나타나는 Linear output layer를 추가한다.
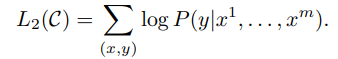
- 위에서 예측한 y를 통해서 L2(Loss function)을 얻게 되고, pre-train 단계에서 얻은 L1을 이용해서 L1, L2를 이용한 fine-tuning을 진행한다.

language modeling을 fine-tuning의 anxiliary objectives로 포함하면 지도 모델 일반화 개선, 융합 가속화 등의 학습에 도움이 된다. L1, L2를 위 식에 대입하고, 최적화시킨다.
W_y와 구분 기호 tokens에 대한 embedding 만 있으면 fine-tuning이 가능하다.
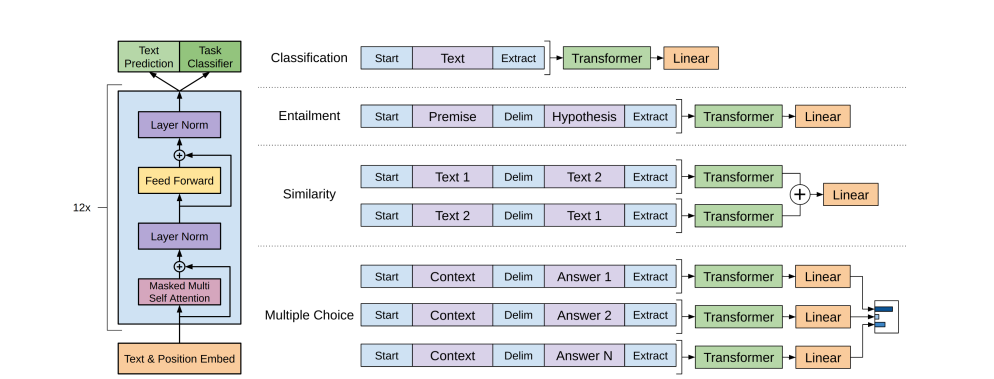
전체적인 구조인데, 왼쪽 그림은 Transformer architecture와 training objectives를 사용한 부분이다. 특징적으로 Transformer의 decoder를 사용하고 있지만, cross-attention 부분이 빠진 것을 볼 수 있다. 오른쪽 그림은 다른 tasks 들에 fine-tuning을 위한 Input을 보여주는 그림인데, 논문에서는 우리가 token sequences에 있는 모든 구조화된 inputs 들을 pre-trained model로 처리하고 이어서 linear와 softmax layer를 덧붙이면 된다고 말하고 있다.
3.3 Task-specific input transformations
여기서 우리는 각 task마다 input transformations 들을 살펴볼 것이다.
1. Text Classification : 직접 모델을 fine-tune 하면 된다. 사전 학습 모델은 연속된 text의 시퀀스에 대해 훈련되었기 때문에 tasks의 적용에 수정이 필요하다. 이전 연구에서는 전이 학습을 기반으로 아키텍쳐 학습을 제안했으나, 상당량의 task-specific customization을 도입하고, 추가 아키텍쳐 구성 요소에 전이학습을 적용하지는 못했다. 대신에 traversal style approach를 사용한다.
2. Text entailment : premise p를 넣고, hypothesis h와 delimiter token으로 구성된다.
3. Similarity : 두 문장을 비교하여 유사도를 측정하는 task로 두 개의 시퀀스 표현을 생성한다. h_l^m 선형 출력 레이어에 공급되기 전에 요소별로 추가하게 된다.
4. QA, Commonsense Reasoning : context z, question q, 가능한 answer {a_k}가 필요하다. context와 question과 가능한 answer를 연결하고, 그 사이에 구분 기호 토큰 [z, q, $, a_k]를 추가한다. 각 시퀀스가 모델에 독립적으로 처리되고, softmax layer를 통해 정규화 되어 가능한 답변에 대한 output distribution을 생성하게 된다.
Experiment
각 task에 Supervised fine-tuning을 실시한 결과들을 알아보자.
Natural Language Infernece

거의 대부분이 SOTA를 기록한다.
QA and Commonsense reasoning
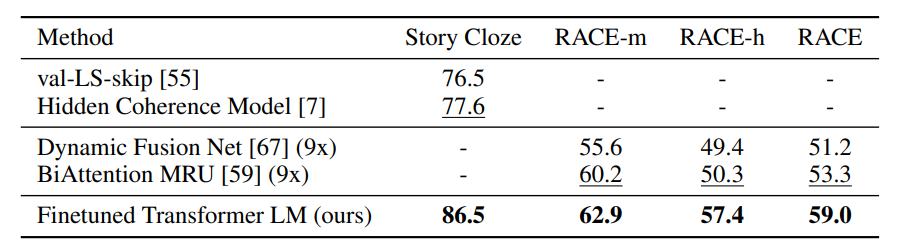
여기서도 모두 SOTA
Semantic Similarity & Classification

여기서도 거의 대부분 SOTA
이렇게 12개의 datasets 들 중 9개에서 SOTA의 결과를 얻게 되고 많은 cases 들에서 outperforming ensembles로 평가된다.
Analysis

왼쪽 그래프의 경우 pre-trained 언어 모델인 RACE와 MultiNLI 로 layers들의 수를 증가시켜서 transferring하는 것에 대한 효과를 보여준다. 오른쪽 그래프의 경우 LM 사전 학습 업데이트의 함수로 다양한 작업에 대한 zero-shot 성능의 변화를 보여주는 그래프이다.
Ablation studies

1. NLP, QQP 같은 큰 데이터셋에서는 Auxiliary Objective가 매우 도움이 된다. but, 작은 데이터셋에서는 오히려 도움이 되지 않는다.
2. LSTM과 Transformers를 비교하면 5.6 average score가 LSTM에서 drop한다.
3. pre-training 없이 supervised target tasks를 직접적으로 trained 했을 때, 모든 tasks에서 성능이 낮아지게 된다. 약 14.8% decrease 하게 된다.
Conclusion
generative pre-training과 차별화된 fine-tuning을 통한 자연어 이해에 강력한 모델이다.
다양한 corpus에서 긴 연속적인 text를 pre-training 하고, 긴 범위의 dependencies 들을 처리하면 성공적인 transferred to solving tasks가 가능하다.(QA, 유사성 평가, entailment, text classification 등)
Unsupervised pre-training을 사용하는 것으로 성능을 높이는 것이 기계 학습의 중요한 목표인 만큼 Transformers + text with long range dependencies가 approach에 최고의 성능을 보장 할 수 있을 것이다.
728x90'Internship_LLM' 카테고리의 다른 글
Instruction finetuning & Self-Instruct (0) 2024.01.26 SELF-INSTRUCT 논문 리뷰 (0) 2024.01.24 BERT 논문 리뷰 (0) 2024.01.09 Attention Is All You Need - Transformer 논문 리뷰 (2) 2024.01.04 Attention 초기 논문 리뷰 (3) 2024.01.04