-
SELF-INSTRUCT 논문 리뷰Internship_LLM 2024. 1. 24. 17:46728x90
Instruction dataset에 대한 가공을 끝낸 후, 이어서 self-instruct에 대한 논문을 리뷰해보면 좋을 것 같아 선택한 논문이다.
instruction 데이터를 자체적으로 생성하여 수준 높은 instruction dataset을 구축할 수 있다는 논문이다.
[2212.10560] Self-Instruct: Aligning Language Models with Self-Generated Instructions (arxiv.org)
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Large "instruction-tuned" language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in
arxiv.org
※ Abstract
"instruction-tuned" LLM은 새로운 tasks에서 zero-shot 상황에서의 주목할만한 능력을 증명해냈다.
그럼에도 불구하고, human-written instruction data에 종종 너무 의존하게 되어, tuning 된 모델의 객관성을 방해하는 경향이 있다고 논문은 이야기 하고 있다.
"SELF - INSTRUCT" : pre-trained 된 언어 모델에서 bootstrap을 실행하여 사전 학습된 언어 모델의 instruction - following 기능을 향상시키기 위한 프레임워크
Abstract에서 말하는 SELF-INSTRUCT의 정의는 이와 같다. Conclusion 까지 SELF-INSTRUCT 자체의 정의가 점점 더 구체화되게 되니, 정의에 주목해서 논문을 읽는 것이 중요하다.
기본적으로 구성된 pipeline은 언어 모델의 "Instruction, input, output" sample 들을 생성하고, 유효하지 않거나 유사한 샘플들을 필터링 한 후 원본 모델을 파인튜닝하는 방식을 가진다.
SELF-INSTRUCT로 생성한 dataset을 GPT3에 적용한 결과 33% 이상의 개선된 성능을 보여주며, private user data와 human annotation을 사용한 InstructGPT 보다 5% 정도 격차의 성능을 보여준다.
-> 전문가가 작성한 instruction 큐레이팅, 인간의 평가들을 거친 self-instruction으로 GPT3을 튜닝하게 되면, 기존 public instruction datasets를 사용하는 것보다 성능이 뛰어나고, 절대적으로는 InstructGPT에 5% 정도만의 격차가 밀리는 유사한 성능을 보여주게 된다.
1. Introduction
최근 NLP에서는 모델을 만들기 위해 자연어 instruction을 따른다. 이러한 발전은 pre-trained LM, human wirtten instruction data(PROMPTSOURCE), (SUPER-NATURLINSTRUCTIONS) 들을 통해 박차를 가해왔다.
하지만, instruction data의 수집은 비싸고, 종종 대부분의 인간 세대가 대중적인 NLP tasks 들에만 집중하게 되면서 다양한 작업과 설명 방법을 포괄하지 못하다보니 다양성이 제한되는 경향이 있다.
다시 말해, <SELF-INSTRUCTION>은 모델로 부터 자체적인 instructional signals를 사용하여, pre-trained LM을 instruction-tuning 하기 위한 자동적인 과정을 말한다. 전반적으로 bootstrapping algorithm을 가지는데, 전체를 생성하는 데 사용되는 manually-written task로 작성된 작업의 제한적인 seed로 시작하게 된다.
1) first-phase
- 새로운 tasks에 대한 instruction을 생성하라는 메시지 표시 : 이 작업을 통해 기존의 instructions 모음을 활용해서 새로운 tasks를 정의하는 광범위한 instructions를 생성할 수 있다.
2) 새로 생성된 instructions 집합이 주어지면, 프레임워크가 새로운 input-output instances를 생성하고, instruction-tuning을 supervising 하는데 사용하게 된다.
3) task pool에 가치있는 남은 tasks 들을 추가하기 전에 다양한 휴리스틱스들이 자동적으로 필터링 된 low-quality or repeated instructions를 사용하게 된다.

위와 같은 bootstrap 기법이 기본이 되며, 이는 vanilla GPT3을 사용해서 생성한 instruction data로부터 task를 선택한 것이다.
- GPT3 self-inst를 생성 : GPT3 보다 33.1% 성능이 개선됨. InstructGPT 보다 5% 격차만 나는 broad range of instruction 능력을 보여준다.(broad range of instruction 능력 : 다른 공공적으로 이용가능한 instruction datasets)
<Contribution Summary>
(1) SELF-INSTRUCT : human-labeled data를 최소화하면서 instruction을 유도하는 방법
(2) 광범위한 instruction-tuning 실험을 통해 효과를 증명함
(3) 52K의 큰 합성 instructions dataset을 내놓음. 빌딩을 위한 manually written novel task를 셋팅. 미래 instruction following model을 평가함.
2. Method
대규모 instruction data에 annotation을 달아주는 것은 인간에게는 매우 어려운 작업이다.
-> 1) 창의성, 2) 전문성 이 필요하기 때문.
< vanilla pre-trained LM으로 tasks를 생성 -> 생성된 데이터를 필터링 -> 생성된 데이터로 instruction 튜닝 -> 튜닝된 instruction이 task pool로 들어감 >
이 과정을 반복하면서 LM이 instruction을 더 잘 따르도록 한다.

위 그림의 flow를 그대로 따라가면서 데이터를 생성하게 된다.
2.1 Defining Instruction Data
- 우리가 생성하려는 instruction data는 instruction sef인 {I_t}를 포함하며, 각각의 자연어로 task t로 정의된다.
- Task t는 n_t >= 1인 input-output instances로 아래와 같은 식을 따른다.
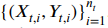
- model M은 task instruction과 그와 일치하는 input이 주어지게 되면 output을 내놓는 것으로 기대하게 되며, 아래와 같은 식을 따른다.

여기서 i 집합은 { 1, ..., n_t } 이다.
- 이 때, instruction 과 instance output에 엄격한 경계는 따로 없다.
- 데이터 포맷의 다양성을 위해, instructions 에 추가적인 input을 요구하지는 않는다. (X is empty)
2.2 Automatic Instruction Data Generation
- 데이터 생성 파이프라인은 크게 4단계로 나뉘게 된다.
1) task instruction 생성
2) instruction이 분류작업을 대표한다면 결정
3) input first or output first 접근으로 instance를 생성
4) low-quality data를 필터링
Instruction Generation.
- 작은 human-written instructions 집합에서 부트스트랩 방식으로 새로운 instructions 를 생성
- 175개 task의 pool에 초기화
- 모든 단계에서, 8 task instruction을 이 pool로 in-context 예시 샘플링
- 8 instructions 중 6개는 human-written 작업, 2개는 다양성 촉진을 위한 이전 단계의 모델 생성 작업에서 나옴
Classification Task Identification
- Classification, Non Classification 각 task에서 다른 접근 방식이 필요하다.
- 12개 Classification instructions, 19개 Non-Classification instructions를 사용해서 few-shot 방식으로 LM prompt를 표시한다.
Instance Generation
- instructions와 task type이 주어지면, 독립적으로 각각의 instances를 생성했다. 하지만, 이 작업을 위해서는 instruction을 기반으로 target task에 대해서 이해한 모델이 필요하고, 추가적인 input도 필요로 한다. 이것들을 모두 생성시켜 줘야만 output을 생성해 낼 수 있어 상당한 어려움이 따른다. 이 문제는 pretrained LM이 instruction-input-output in-context를 prompt 할 때 해결이 가능하다.
- Input first Approach로 LM에 instruction 기반의 input field를 요청하고, 일치하는 output을 생성할 수 있다. 그러나, 이 접근 방식은 one-label에 편향된 input을 생성하는 것은 가능하지만, Classification에서 문제에 봉착하게 된다. 이 문제를 해결하기 위해서 분류 문제에서는 가능한 class label을 먼저 생성하고, 각 class label에 input 생성을 조건화하는 output first approach를 추가로 논문에서는 제안하고 있다.
∴ Non-Classification - Input first Approach
∴ Classification - Output first Approach
Filtering and Postprocessing
- 다양성 장려를 위해, 기존 instruction과 ROUGE-L 유사성이 0.7 미만인 경우 task pool에 새 instruction을 추가한다.
- LM에서 처리할 수 없는 특수한 keywords를 포함하는 instruction은 제외한다.
- 각 instruction을 위한 새 instances를 생성할 때, 정확히 동일하거나 input이 같아도 output이 다를 경우 filter한다.
- 가치 없는 생성도 휴리스틱스를 기본으로 필터링한다.
2.3 Finetuning the LM to Follow Instructions
- large-scale instruction data를 생성한 후, original LM을 fine-tune 하는 방식.
- insturction과 instance input을 prompt로 연결하고 supervised 방식으로 instance output을 생성하는 모델을 train 시킨다.
- 다른 포맷에도 모델을 견고하게 하기 위해, instruction을 인코딩한 다양한 템플릿들을 사용하고, instance input을 함께 사용한다.
3. SELF-INSTRUCT Data From GPT3
3.1 Statistics
- 총 52K instructions와 필터링 후에 82K가 넘는 instructions에 일치하는 instances를 생성

3.2 Diversity
- verb-noun 구조를 생성된 instructions에서 식별하여 무슨 type의 instruction이 생성되는지, 얼마나 타당한지를 연구한다.
- Berkely Neural Parser를 사용해서 instructions를 분석, root(근)과 가장 가까운 동사를 추출, noun 개체 추출.
- 52445 instructions 들 중 26559개에서 1) complex clauses, 2) question frame 구조를 발견.

- top 20의 근동사, top 4의 명사를 표시(전체집합의 14%를 차지)
-> 전체적으로 이 instruction에 대한 다양한 의도와 text 포맷을 볼 수 있다.

- prompt를 사용한 seed instruction과 생성된 instruction이 얼마나 다른지 추가로 연구한다.
-> 175개의 seed instructions 들과 ROUGE-L의 가장 높은 overlap을 계산하게 됨.
∴ 매우 상당 수의 생성된 새 instructions가 seed와 거의 overlap 되지 않아 좋은 결과를 보여준다.

- 위 자료는 instructions 길이, instance inputs, instance outputs의 다양성을 증명한 자료이다.
3.3 Quality
- 200개의 instruction을 random sampling하고, 각 instruction 당 1개 instance를 random select했다.
-> 생성된 instructions 들은 대부분 의미 있고, 생성된 instance 들은 어느 정도 noise를 포함하고 있었다. 하지만, 대부분 올바른 형식을 띄고 있으며, 부분적으로는 정확하여 training된 모델이 useful한 guidance를 제공할 수 있다.
4. Result
4.1 GPT3 self-inst : finetuning GPT3 on its own instruction data
- instruction-generated instruction data가 주어지면, GPT3 model로 instruction tuning을 실행한다.
- instruction, input, 훈련 모델로 생성된 output 연결을 위해 다양한 템플릿들을 사용했다.
- Open AI API를 사용해서 fine-tuning
- prompt loss weight : 0인 것은 제외, 2 epochs 동안 모델을 훈련
4.2 Baselines
off-the-self-LMs
- T5-GPT3 사용
publicly available instruction tuned models
- T0, Tk-INSTRUCT 2가지 instruction-tuned model을 T5 checkpoint에서 fine-tune했으며, 11B parameters의 큰 버전을 사용했다.
Instruction-tuned GPT3 models
- InstructGPT로 평가했으며, 다른 공개적 self-instruct 훈련이 가능한 isntruction tuning data와의 비교를 위해 T0, Tk-INSTRUCT 모델에 사용한 PROMPTSOURCE, SUPERNI 데이터로 GPT3 모델을 finetuning 했으며, 이를 T0 training, SUPERNI traning이라고 부른다.
4.3 Experiment 1: Zero-Shot Generalization on SUPERNI benchmark
- SUPERNI 평가 세트 사용
- 119 task, 100 instance
- model : in-context 증명 예시 X, tasks들의 정의 O
Resutls

- Vanilla GPT3 -> human instructions를 따르지 못한다. 반복적으로 텍스트를 생성하고, 적절하지도 않고, 언제 종료될지도 모른다.
- GPT3 self-inst -> T0, T0 training set에서 fine-tuned된 모델보다 나은 성능으로 InstructGPT와 성능이 거의 유사하다.
∴ SUPERNI 훈련이 여전히 평가 set에서 더 나은 성능을 보여주지만, GPT3 self-inst와의 결합을 통해 추가적인 이득을 얻고, 보완 데이터의 가치를 증명했다.
4.4 Experiment2: Generalization to User-oriented Instructions on Novel Tasks
- 기존 NLP에서는 SUPERNI의 포괄성에도 불구하고, 왜곡된 분류, 연구 목적으로 대부분의 NLP tasks들을 사용했었다.
-> 실용적으로 instruction-following models들을 접근하기 위해, 논문 저자들은 사용자 지향 어플리케이션에 동기를 받은 새 instruct set을 curate한다.
-> tasks 들의 스타일과 포맷을 다양화하는 것이 목적
-> 총 252 instruction을 생성(개당 instance)
Human evaluation setup
- 다양한 tasks들의 평가 세트에서 모델 성능을 평가하는 것은 다른 task가 다른 전문성을 요구하기 때문에 어렵다.
-> 평가를 위해, instruction 작성자에게 model의 예측을 판단하도록 요청했으며, 평가자들에게 효율성과 정확성 판단을 output 비율로 요청했다.
- 모델의 output의 quality를 카테고리화하기 위해 4개의 level 시스템을 구현했다.
1. RATING A : 응답이 유효, 만족
2. RATING B : 응답 허용은 가능 하지만 작은 오류, 불완전성이 존재
3. RATING C : 응답이 관련성 있음, instruction에 응답은 하지만 내용이 중요한 오류 존재
4. RATING D : 응답이 관련성 없음, 완전히 유효하지 않음.
Results
- GPT3 self-inst는 InstructGPT001과 성능이 거의 유사하고, 5% 정도만 뒤쳐진다.
- InstructGPT002, InstructGPT003은 인상적인 instruction-following 능력을 보여준다.
∴ human annotators 사용, 좋은 생성을 내는 reward된 훈련 모델을 사용해서 생성 데이터의 품질을 향상시키는데 미래에 큰 이점이 될 것으로 논문은 생각한다.
4.5 Effect of Data Size and Quality
Data size
- self-instruct는 낮은 비용, no human labeling으로 instruction data를 증가시킬 수 있는 방법이다.
- 서로 다른 수의 instruction을 subsampling하고 생성데이터셋, sampled subsets로 fine-tuning된 GPT3, 252개의 사용자 지향 instruction set에서 결과 모델이 어떻게 수행되는지 평가하는 것으로부터 생성데이터 크기를 분석한다.

- 위 그림을 통해 데이터 사이즈가 커지게 되면 성능 향상이 있다는 것을 알 수 있다. 하지만, 16K 이후에는 거의 유사하다는 것도 파악이 가능하다.
- SUPERNI에서 평가할 때 모델의 성능 향상 정체가 수백개의 instructions에서 더 일찍 발견되기도 했다.
∴ 새로 생성된 데이터가 SUPERNI에서 일반적인 NLP연구와 구별되기 때문이며 다양한 유형의 task에서 더 나은 성능을 얻을 수 있다.
Data quality
- 모델의 성능 향상은 1) 생성 데이터 얻기, 2) less noise를 가지는 더 좋은 supervision 에서 일어난다.
- InstructGPT003을 사용해서 instruction과 input을 가진 우리의 모든 instances의 output field를 재생성하고, 이후 향상된 버전의 data로 GPT3을 fine-tuning한다.
- 위 사진에서, 결과 모델은 원본 데이터 학습 모델보다 10% 성능이 뛰어난것을 볼 수 있다.
- 생성 pipeline으로 초기 데이터를 확보하고, 데이터 품질을 개선한다.
5. Related Work
Instruction-following LMs
- annotated 된 instructional data와 함께 튜닝되면, vanilla LM이 일반적인 언어 instructions를 따르는데 효과적일 수 있다.
- 추가적으로, size, instructional data의 다양성, 보이지 않는 tasks에서 모델 결과의 일반성과 직접적인 연관을 보여준다.
-> 대부분 기존 NLP에 초점을 맞추고 있고, human-annotated instructions에 의존하기 때문에 더 일반화 된 모델로 발전하는데 "병목현상"이 발생한다.
- InstructGPT 수준의 성능을 보여주지만, 구축 process가 불분명하고, 제한된 분명성과 개인 사용자 데이터가 있어 연구가 부족하다.
-> 넓은 범위의 tasks를 커버할 수 있는 large scale의 공공 dataset이 필요하다.
Language models for data generation, augmentation
- SELF-INSTRUCT의 구별된 동기는 기존 NLP에서는 정의되지 않았을 수 있는 새로운 tasks들의 정의를 bootstrap하는 것이다.
- GPT3 모델로 large-scale의 instruction data 생성을 목적으로 한 작업과의 차이
1) SUPERNI를 사용해서 생성된 tasks와의 분포 차이
2) InstructGPT002를 데이터 생성을 위해 사용하는데, 이는 이미 instruct tuning된 모델에서 지식을 증류하지만, 논문 방식은 vanilla LM에만 의존하고 있다.
3) 구체적인 생성 pipeline과 templates가 다름
∴ 그럼에도 불구하고, 이 논문에서의 노력은 instruction data의 확장이 상호보완적이고, 다양한 데이터셋으로부터 이득을 얻을 것이라고 주장하고 있다.
Instruction generation
- SELF-INSTRUCT는 instruction 생성에도 포함되지만, 주된 차이는 task-agnostic이다. task-agnostic이란 새로운 태스크를 처음부터 생성하는 것이다.
Model self-training
- 전형적인 self-training은 훈련 모델로 unlabeled data에 label을 할당하고, 새로운 labeled data로 모델을 향상시키는 것이다.
-> 여러 prompt를 사용해서 구체적인 tasks를 지정, prompt에 일관성 있는 예측을 장려해서 정규화한다.
- unlabeled training data를 추가로 모델 파인 튜닝하여, 추론 시에 직접적용
∴ SELF-INSTRUCT는 self-training과 유사성을 가지나 차이점이 존재한다. 대부분의 self-training 방법은 구체적인 target tasks를 가정할 뿐만 아니라 그 아래의 unlabeled data 예시를 가정하지만, self-instruct는 처음부터 다양한 작업을 생성하는 방식이다.
knowleage distillation
- 더 큰 모델에서 작은 모델로 지식을 전달
- SELF-INSTRUCT는 이 형태를 가지지만, 차이가 있다.
1) distillation의 소스와 타겟이 동일하다. -> 모델 지식이 그 자체로 distilled 된다.
2) distillation의 내용은 instruction task의 형태이다.
Bootstrapping with limited resources
최근 연구 : LM을 사용해서 전문적인 방법의 일부 추론을 bootstrap한다.
- NPPrompt : fine-tuning 없이 의미론적 label에 대한 예측 생성 방법이다. 모델 자체의 임베딩을 사용해서 데이터 샘플의 레이블과 관련된 단어를 자동으로 찾는다. 찾은 단어로 모델 예측 시 레이블로 수동 매핑하는데 대한 의존도를 줄여준다.
- STAR : 소수의 예시와 근거가 없는 대규모 세트를 반복적으로 활용하여 추론을 수행하는 모델 능력을 bootstrap으로 활용한다.
- Self-Correction : 불완전한 생성을 반복적으로 수정하는 방법을 학습하고, 기본 생성기 보다 개선됨을 증명한다.
∴ 전체적으로 instruction 패러다임에서 새로운 tasks들에 bootstrap을 적용하는 것에 중점을 둔다.
Multi-modal instruction-following
- SELF-INSTRUCT : 데이터 확장의 일반적인 접근 방식으로 이러한 셋팅이 잠재적으로 도움이 된다.
6. Conclusion
SELF-INSTRUCT : 자체 생성된 instruction data로 LM의 instruction-following 능력을 향상 시키는 방법
- vanilla GPT3으로 large-scale dataset(52K instruction)을 자동적으로 만들었고, 이 data로 GPT3를 파인튜닝하여 orginal GPT3 보다 SUPERNI에서 33%의 궁극적인 향상을 이끌어냈다.
- GPT3 + self-instruct는 공공 instruction datasets를 사용했으며, 뛰어난 성능을 보이고, InstructGPT001과 거의 유사하다.
논문은 self-instruct가 pretrained LM이 인간 instructions의 지시를 따르도록 하는 첫 단계가 되기를 바라며, 이 데이터를 기반으로 향상을 이끌어내는 것을 희망하면서 마친다.
SELF-INSTRUCT의 정의를 모두 모아서 한 번에 정리해보려고 한다.
1. "SELF - INSTRUCT" : pre-trained 된 언어 모델에서 bootstrap을 실행하여 사전 학습된 언어 모델의 instruction - following 기능을 향상시키기 위한 프레임워크
2. <SELF-INSTRUCTION>은 모델로 부터 자체적인 instructional signals를 사용하여, pre-trained LM을 instruction-tuning 하기 위한 자동적인 과정을 말한다.
3. SELF-INSTRUCT : human-labeled data를 최소화하면서 instruction을 유도하는 방법
4. SELF-INSTRUCT : 자체 생성된 instruction data로 LM의 instruction-following 능력을 향상 시키는 방법
결국 SELF-INSTRUCT라는 것은 pre-trained 된 언어 모델에서 human-labeled data를 최소화하면서 자체적인 instructional signals인 bootstrap을 실행하여 pre-trained 된 언어 모델을 instruction-tuning 하고, 튜닝된 언어 모델의 instruction-following 능력을 향상시키기 위한 프레임워크이다.
728x90'Internship_LLM' 카테고리의 다른 글
LLM Parameters (0) 2024.01.26 Instruction finetuning & Self-Instruct (0) 2024.01.26 GPT - 1.0 논문 리뷰 (0) 2024.01.12 BERT 논문 리뷰 (0) 2024.01.09 Attention Is All You Need - Transformer 논문 리뷰 (2) 2024.01.04