-
Attention 초기 논문 리뷰Internship_LLM 2024. 1. 4. 11:21728x90
기업 인턴을 진행하면서 LLM 연구를 시작하게 되었다.
그 가장 첫번째 발자취는 Attention의 가장 첫 논문인 "Neural Machine Translation By Jointyly Learning To Align And Translate" 을 리뷰하면서 Attention 모델을 이해하는 것이다.
1. Introduction
machine translation에서 최근에는 Neural Machine Translation을 사용하고 있는데, 이는 대부분 encoder-decoder 방식을 사용하는 것이 일반적이다.
- encoder : encoder Neural Network가 문장을 읽고 fixed-length vector 들을 encoding 한다.
- decoder : encoder vector로 부터의 번역을 output하게 되며, fixed-length vector가 입력 문장의 모든 정보를 포함하고 있으며, 문장의 모든 필수 정보를 fixed-length vector로 압축할 수 있어야 한다는 점 때문에 문장이 길 경우 성능이 좋지 않다.
-> 이러한 문제를 해결하기 위해
1) 문장에서 관련성 높은 정보가 위치한 곳을 검색
2) context vector와 소스 위치를 기반으로 목표 단어를 예측 : 연관된 context vecotr와 previous generated target word를 기반으로 목표 단어를 예측
이 두 가지를 제안함으로써 Allign + Translate 모델을 고안하게 되었다.
2. Background
1)
arg max_y p(y | x) : 입력 문장 x에 대해서 가장 높은 확률 y를 찾자.
ⓐ 소스 문장 x encoding -> ⓑ 목표 문장 y decoding
< 가변 길이 소스 문장을 fixed-length vector로 인코딩 >
-> 결과값을 이용해서 < 가변 길이 목표 문장을 높은 확률의 word로 반환하는 디코딩>
2) RNN encoder-decoder
<encoder>
x = (x_1, ..., x_Tx) -> T개 길이의 Sequence 형태
h_t = f(x_t, h_t-1) -> t 시점의 RNN output
c = q(h_1, ..., h_Tx) -> T개 길이의 최종 Output
=> 각 t 시점의 h가 q에 입력되면서 c라는 T 길이의 최종 Output이 형성된다.
<decoder>

c : encoder output(context vector)
{y_1, ..., y_t-1} : t 이전 시점의 word
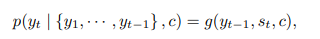
nonlinear g 함수를 이용해서 예측
s : RNN 셀의 output
c : context vector
결론 : 이전 시점의 x를 Input하고 encoding을 거쳐서 나온 RNN 셀의 output을 모아 g 함수로 decoding 하여 예측!!!!
가장 높은 확률 y를 예측하는 것이 목적!!!!
3. Learning to ALIGN and TRANSLATE
bidirectional RNN으로 구성된 새로운 model
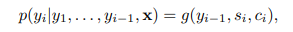
s_i는 RNN의 i 시점 hidden state

Model(Decoder)

1) X의 입력을 받는 부분이 h 시점에서 양쪽으로 학습하는 bidirectional 모양
2) 각 h 시점의 output a_t,T를 weigthed sum 하여 y_t에 입력(T : X의 길이, t : y의 예측 현재 시점)
-> X와 c_i가 이전 model과의 차이로 별개의 context vector로 확률이 결정된다.
3) context vector

- 예측 시점 y의 시점 i에 대한 context vector. 전체 X(annotations h_i)로 부터의 weighted sum

alpha : e_ij의 softmax 함수
e_ij : 위치 j 주변의 입력과 위치 i의 출력의 일치 score 정렬모델
※ alpha_ij, e_ij는 다음 상태 S_i를 결정, y_i를 생성할 때 이전 S_i-1에 대한 h_j의 중요성을 반영
※ Decoder가 Attention mechanism을 갖도록 함으로써 encoder가 모든 문장의 모든 정보를 fixed-length vector로 encoding하는 부담을 감소시킴.
=> Spread throughout the sequence!!! decoder에 의한 선택적 검색이 가능해진다.
4) Encoder : bidrectional RNN
∴ 제안하는 모델에서는 preceding words와 following words 모두를 요약하고자 한다.
=> 음성 인식에 성공적으로 사용되었던 bidirectional RNN을 제안.

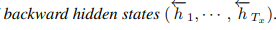
=> x_j 단어를 얻기 위해서 h_j = [forward hidden states(h_j), backward hidden states(h_j)] 구성 시에 h_j가 preceding words와 following words를 모두 요약할 수 있다.
=> RNN 자체가 최근 inputs를 더 잘 대표하는 경향이 있어, h_j가 x_j 단어에 더 focusing된다. - decoder 시 context vector 계산에 추후 활용
4. Conculsion
Problem : 기존 encoder-decoder 방식에서는 모든 문장을 fixed-length vector로 넣고 번역을 시행하다보니 긴 문장에서 효율이 떨어지게 된다.
-> Attention Model : 각 단어에 집중하기 위해 Bidirectional RNN을 encoder로 사용, 정확한 위치와 단어에 focusing을 할 수 있게 되어 긴 문장에서도 성능이 좋음.
논문 전체를 포괄할 수 있는 중요한 문장이 두 가지 정도 있어서 소개를 하고 논문 리뷰를 마무리하려한다.
"model focus only on information relevant to the generation of the next target word."
"extended the basic encoder-decoder by letting a model search for a set of input words, or their annotations computed by an encoder, when generating each target word."
728x90'Internship_LLM' 카테고리의 다른 글
Instruction finetuning & Self-Instruct (0) 2024.01.26 SELF-INSTRUCT 논문 리뷰 (0) 2024.01.24 GPT - 1.0 논문 리뷰 (0) 2024.01.12 BERT 논문 리뷰 (0) 2024.01.09 Attention Is All You Need - Transformer 논문 리뷰 (2) 2024.01.04