-
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings 논문 리뷰LLM papers 2024. 4. 28. 17:18728x90
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings
Augmenting large language models (LLMs) with external tools has emerged as a promising approach to solving complex problems. However, traditional methods, which finetune LLMs with tool demonstration data, can be both costly and restricted to a predefined s
arxiv.org
Abstract
본 논문은 ToolkenGPT라고 하는 새로운 방식을 제시하고 있다. 각 도구를 toolken으로 표현하고 이를 학습해서 동일한 방식으로 도구 호출을 가능하게 한다. toolken 임베딩 학습을 위한 광범위한 데모 데이터를 허용함으로써 도구 사용을 개선한다. 수치적 추론, 지식 기반 질문 응답, 구현된 계획 생성과 같은 다양한 도메인에서 ToolkenGPT 접근법은 LLM에 도구를 효과적으로 통합하고 다양한 최신 기준들을 크게 능가한다고 설명하고 있다.
Introduction
LLM의 연구 접근법에는 두 가지 주요 패러다임이 있다. 첫번째는 특정 도구의 학습을 위한 LLM fine-tuning이다. 이 방식은 유망한 결과를 낼 수 있지만, 계산 비용이 많이 들고 새로운 도구 적응에 제한적이다. 두번째는 Incontext learning이다. 이 방식에서 LLM은 프롬프트에 제공된 Incontext 데모를 통해 도구 사용 방법을 학습한다. 이 방식은 Langchain과 chatGPT plugin과 같은 응용 프로그램을 이끌어냈다. 하지만, context 길이의 내재적 한계로 인해 새로운 도구를 몇 가지 예제를 통해서 마스터하는 것은 어려울 수 있다는 문제가 있다.
본 논문에서는 LLM fine-tuning 없이도 새로운 도구에 빠르게 적응할 수 있도록 하는 해결책으로 ToolkenGPT를 소개한다. ToolkenGPT는 파인튜닝과 인컨텍스트러닝의 강점을 결합하고 각 한계는 피한다. ToolkenGPT는 각 도구를 새로운 토큰(toolken)으로 표현하여 어휘를 확장하는 것이 핵심적인 아이디어이다. 각 도구가 일반 단어 토큰 임베딩처럼 LLM의 헤드에 삽입되고, 생성 중에 toolken이 예측되면 LLM이 도구를 실행하기 위해 인수를 생성하는 특별 모드로 전환된다. 이 방식을 사용하면 LLM이 해당 도구에 최적화될 수 있으며, toolken 임베딩만을 학습하게 됨으로써 효율적으로 작동할 수 있다.
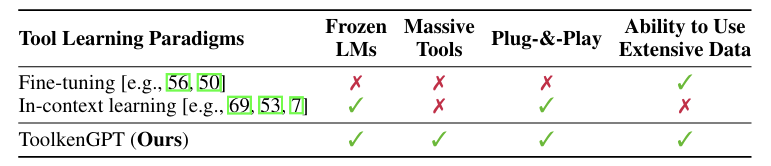
ToolkenGPT와 Fine-tuning, In-context learning을 비교한 표인데, 각 한계를 피하고, 장점들을 확보한 것을 볼 수 있다.
복잡한 수치추론문제를 예시로 제공하고 있는데, 이 경우에 수학 도구를 이용하면서 CoT나 ReAct 기법의 성능을 크게 능가한다. 지식 기반 질문 응답의 경우에서도 ToolkenGPT가 200개 이상의 관계 API를 지식 기반으로 통합해서 사실적인 예측을 가능하게 한다.
ToolkenGPT for Mastering Massive Tools

ToolkenGPT 프레임워크를 본 논문에서는 복잡한 수식으로 제공하고 있지만, 시각자료로 이해하는 것이 가장 좋을 것 같다. 전체적인 개요는 위 그림과 같다.
Toolken 임베딩은 일반 단어 토큰처럼 언어 모델의 헤드에 추가되며, 문제를 해결하기 위한 Reasoning mode에서는 LLM이 평소와 같이 텍스트를 생성하지만, 추가된 toolken이 다음 토큰 생성을 위해 고려가 된다.
Toolken이 예측되면
1. LLM이 Tool mode로 전환되어 동일한 도구의 몇 가지 데모를 제공하고 인수를 완성한다.
2. 도구 호출이 실행된다.
3. 결과가 텍스트로 돌아와 Reasoning 모드에서 최종 답변을 생성시킨다.
Framework Overview
각 toolken은 toolken 임베딩 벡터로 매개변수화되며, toolken 임베딩 집합을 행렬로 표현한다. 훈련된 toolken 임베딩을 가지고 있다면, LLM은 기본적으로 추론 모드에서 다음 토큰을 생성한다.

LLM이 다음과 같은 확률로 다음 토큰을 예측한다. 다음 토큰은 단어 토큰 or toolken일 수 있다. 이전 방법들이 도구 학습을 완전히 incontext learning에 의존하는 것과 대조적으로 ToolkenGPT 프레임워크는 인수를 완성하는 작업만 incontext learning으로 처리한다. 이렇게 완성된 인수는 지정된 도구에 보내져서 실행되고, 반환 값은 추론 모드에서 텍스트로 보내지게 된다.
Learning Toolken Embeddings
프레임워크가 원래 LLM 매개변수를 그대로 유지하면서 toolken 임베딩과 관련된 최소한의 추가 훈련 오버헤드를 도입한다. 임베딩 행렬이 prompt tuning이나 prefix tuning 과는 달리, LLM 매개변수의 주요본체를 통해서 gradient가 흐르는 것을 요구하지 않아서 훨씬 안정적이고 효율적인 훈련이 가능하게 된다.
toolken 임베딩 튜닝과 LLM inference와 거의 동일한 GPU 메모리를 유지하고 있으며, 새로운 도구가 추가될 때마다 확장되게 된다. 또한, 대규모 데모에서 toolken 임베딩을 튜닝할 수 있다.
본 논문은 도구 데모와 함께 toolken 임베딩을 학습하는 데 초점을 맞춘다. 먼저 훈련 데이터의 형식과 훈련 목표를 설정한다. 예를 들어, "the area is 256 square feet ..."는 단어 토큰 시퀀스 s = (“the”, “area”, “is”, “2”, “5”, “6”, “square”, “feet”, ...)로 토큰화 될 수 있는 것이다. 여기서 toolken을 예측해야 할 때를 나타내기 위해서 단어 토큰과 toolken이 혼합된 병렬 시퀀스 s′ = (“the”, “area”, “is”, “[square]”, “[N/A]”, “[N/A]”, “square”, “feet”, ...)가 필요하게 되고, 여기서 ("2", "5", "6") 부분 시퀀스는 s에서 도구 결과가 채워져야 할 부분이 된다. s'에서 해당 도구 호출의 첫 번째 토큰을 toolken으로 선택하고, 다음 토큰들은 [N/A]로 채워져서 손실 계산에서 무시된다.

따라서 ToolkenGPT의 훈련 목표는 다음과 같은 식으로 표현이 가능하다. 도구 호출을 위해 LLM은 처음에 toolken을 예측하는 것 뿐이고, 그 후에는 도구 호출의 반환값이 텍스트에 다시 채워지게 된다.
Experiment
Numerical Reasoning

Knowledge-based Question Answering

Embodied Plan Generation

Grounding : 모든 행동과 객체가 환경에 구체화될 수 있는 스크립트의 비율
Executable : 어떠한 규칙도 위반하지 않고 VirtualHome에서 실행될 수 있는 스크립트의 비율
Success : 올바른 최종 상태로 이어지는 스크립트의 비율
Success(R) : 편안한 변형, 반드시 그 상태에서 끝나지는 않지만 올바른 최종 상태에 도달한 스크립트의 비율
ToolkenGPT는 자연스럽게 유효한 행동과 객체를 예측하고, 더 많은 훈련 과제에서 toolken 임베딩을 학습함으로써 가장 높은 성공률을 달성하게 된다.

모든 기준선이 [SIT] <desk>를 예측하더라도, VirtualHome에서 [SIT]은 "앉다"를 의미하며 책상은 앉을 수 없는 것으로 간주되는데, ToolkenGPT만 이 규칙을 성공적으로 학습하고 [SIT] <chair>를 예측한다.
Computational Cost
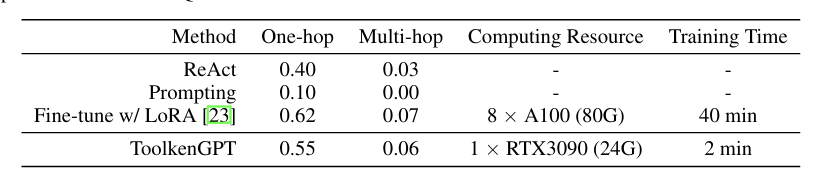
fine-tuning 된 LLM은 FuncQA 데이터셋에서 ToolkenGPT보다 약간 더 나은 성능을 보인다. LoRA도 fine-tuning에 필요한 시간 소모는 ToolkenGPT의 toolken 임베딩과 비교할 때 상당히 많은 편이다. ToolkenGPT는 각 도구에 대한 매개변수가 분리되어 있기 때문에, 다양한 도구를 plug and play 할 수 있는 이점이 있다.
Ablation study

Tool mode에서는 LLM에 선택된 도구만을 사용한 데모를 프롬프트해서 ReAct 프롬프트보다 인수 완성에 더 관련된 지식을 제공한다. Tool mode를 추가하면 인수완성의 정확도를 더 높일 수 있다. 하지만, ToolkenGPT를 이용하게 되면 인수 완성의 정확도를 더욱 크게 능가하게 된다. 이를 통해 toolken 임베딩이 LLM에 도구 호출 시기와 도구 선택을 효과적으로 돕는것을 알 수 있다.
Conclusion
본 논문에서 소개한 ToolkenGPT는 비싼 fine-tuning 없이 외부 도구로 고정된 LLM을 증강시키는 방식이다. 각 도구에 대한 toolken 임베딩을 도입해서 LLM이 단어 토큰을 생성하는 것처럼 다양한 도구를 호출하고 사용할 수 있게 한다. 이 방식을 통해서 fine-tuning과 incontext learning의 한계를 극복하여 LLM이 더 많은 도구 세트와 데모 데이터를 사용해서 toolken 임베딩을 학습할 수 있게 한다. 이를 통해서 수치적 추론, 지식 기반 QA, 실체화된 계획 생성과 같은 task에서 LLM의 성능을 높일 수 있게 된다.
본 논문을 리뷰하면서 LLM의 파인튜닝을 통한 작업들이 비싼 cost와 다양한 한계점이 존재하는 것을 인식하고 개선하는 방식들에 대한 최신 트렌드가 외부 도구들을 이용하는 방식이라는 것을 알 수 있었다. 지난번 리뷰했던 Toolformer와 유사하게 이 방식도 외부 도구들을 토큰화해서 LLM의 성능을 높이는 것이 핵심이었다. 최근 LLM의 트렌드가 어떤 것인지 도구를 이용하는 논문을 두 편 연속으로 리뷰하면서 몸소 제대로 느낄 수 있었다고 생각한다.
728x90'LLM papers' 카테고리의 다른 글
Scaling Data-Constrained Language Models 논문 리뷰 (0) 2024.05.11 QLoRA: Efficient Finetuning of Quantized LLMs 논문 리뷰 (0) 2024.05.04 Toolformer: Language Models Can Teach Themselves to Use Tools 논문 리뷰 (0) 2024.04.02 Jailbroken: How Does LLM Safety Training Fail? 논문 리뷰 (1) 2024.03.27 Are Emergent Abilities of Large Language Models a Mirage? (0) 2024.03.20