-
Scaling Data-Constrained Language Models 논문 리뷰LLM papers 2024. 5. 11. 15:12728x90
[2305.16264] Scaling Data-Constrained Language Models (arxiv.org)
Scaling Data-Constrained Language Models
The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. Motivate
arxiv.org
Abstract
Language Model을 스케일링하는 추세는 매개변수 수와 훈련 데이터셋 크기를 증가시키는 것이다. 이 추세로 보면 훈련 데이터셋 크기가 인터넷에 사용 가능한 텍스트 데이터 양에 제한될 수 있다. 이런 동기를 통해 본 논문에서는 데이터 반복과 계산 예산의 정도를 다양하게 해서 대규모 실험 세트를 수행한다. 전체적인 실험을 보면, 고정된 계산 예산으로 제한된 데이터를 사용해서 훈련할 때 최대 4 epoch 반복 데이터는 loss에 미미한 변화를 보이지만, 반복이 더 많아질수록 추가 계산의 가치가 점점 감소하게 되면서 결국 제로가 되게 된다. 본 논문에서는 반복된 토큰과 과도한 매개변수의 가치 감소를 고려한 계산 최적성 스케일링 법칙을 제안한다.
Introduction
본 논문의 Introduction에서는 계산 최적화 언어 모델에서 같은 계산 예산으로 더 작은 모델을 더 많은 데이터로 훈련시킬 때 더 좋은 성능을 달성할 수 있다는 것을 말하면서 시작하고 있다. 하지만, LLMs는 이미 데이터 제약을 받고 있고, Chinchilla 스케일링 법칙과 점점 더 큰 모델을 훈련하는 추세를 고려할 때, 고품질 데이터가 모두 고갈될 것으로 예상된다. 본 논문은 "그렇다면, 데이터가 부족할 때 우리는 무엇을 해야할까?" 라는 근본적인 질문을 제기한다.
본 논문에서는 데이터 제약 환경에서 대규모 언어 모델의 스케일링을 조사하고, LLM의 여러 에폭에 걸쳐 반복 데이터로 훈련하는 것이 스케일링에 미치는 영향을 고찰한다. 이 연구를 통해 본 논문은 LLM 훈련에 있어서 여러 에폭의 영향을 정량화하여 실무자들이 모델을 스케일링할 때 계산을 어떻게 할당할지 결정할 수 있도록 하는 것이 주된 초점이다.

이 그림을 보면, 단일 에폭에서 훈련된 모델이 일관되게 최고의 검증 손실을 보이지만, 최대 4 epoch까지 훈련된 모델 간에는 차이가 거의 없어서 하위 작업 성능에도 차이가 나지 않는 것을 볼 수 있다. 추가 에폭은 유익하지만, 결국 return은 제로로 감소하게 된다. 데이터 제약 체제에서는 매개변수와 에폭을 모두 더 많이 할당하는 것이 필요하고, 에폭을 약간 더 빠르게 스케일링할 필요가 있다.
본 논문에서는 마지막으로, 데이터 제약 체제에서는 하위 정확도를 개선하기 위해 새로운 자연어 데이터를 추가하지 않고 반복 외에도 코드 토큰을 추가하고 데이터 필터링을 완화하는 접근법을 고려한다. 필터링의 경우에는 노이즈가 많은 데이터셋과 깨끗한 데이터셋 모두에서 난해성 및 중복 제거 필터링 전략을 검토하고, 데이터 필터링이 주로 노이즈가 많은 데이터셋에 효과적이라는 것을 발견했다.
Background
대규모 모델의 스케일링에서는 (Allocation) 자원의 최적 균형은 무엇인가? (return) 추가 자원의 기대 가치는 얼마인가? 이 두 가지 질문이 주된 관심사이다. LLMs를 스케일링할 때, 자원은 FLOPs compute이며, 더 큰 모델을 훈련하거나 더 많은 단계로 훈련하는 데 할당될 수 있다.
우리의 주된 목표는 N과 D에 대한 최적의 할당을 통해 Loss(L)을 최소화하는 것이다.
return은 멱법칙을 따르며, 훈련에 사용된 계산의 양에 따라 Loss가 멱법칙으로 스케일된다.
Allocation은 균형을 이루며, 자원이 매개변수 스케일링과 데이터 사이에 대략적으로 균등 분배된다.
Chinchilla는 스케일링 예측을 만들기 위해 세 가지 방법을 사용한다고 한다.
1. (Fixed Parameters) 고정된 모델 크기로 다양한 양의 데이터에서 훈련한다.
2. (Fixed FLOPs) 매개변수와 훈련 토큰이 변하는 동안 고정된 계산으로 훈련한다.
3. (Parametric Fit) 손실에 대한 공식을 도출하고 적합시킨다.
Parametric Fit을 위해 Loss(L)은 매개변수(N)과 훈련 토큰(D)의 함수로 표현된다.
이 학습 변수들을 사용해서 계산(C)를 N과 D에 최적으로 할당하는 방법을 제안한다.
이 방법에서 alpha = beta 이므로 N과 D는 계산 최적 훈련을 위해 비례적으로 스케일링되어야 한다.
Method: Data-Constrained Scaling Laws
본 논문의 해당 연구에서의 목표는 수정된 L(N, D)식을 도입하고 대규모 실험 데이터에 적합시키는 것이다.
고려하는 주요 방법은 데이터를 반복하는 것이다. 같은 데이터에 여러 epochs 동안 FLOPs를 할당한다. 고유 데이터 예산 DC가 주어지면, Chinchilla의 총 데이터 항 D를 UD(사용된 고유 토큰의 수), RD(반복횟수) 두 부분으로 나눈다. 총 훈련 토큰 D와 데이터 예산 DC가 주어졌을 때, 와 𝑅𝐷=(𝐷/𝑈𝐷)−1
해당 식으로 최적화 할 수 있다.
그 후 매개변수 항 N을 UN(UD에 최적으로 맞는 기본 매개변수 수), RN(초기 할당을 반복하는 횟수) 대칭적으로 두 부분으로 나눈다. 그 후 N_opt 공식에 고유 토큰 사용에 대한 최적 계산 예산을 찾아 입력하고 UN 값을 도출한다.
UN = min{N_opt, N}으로 구할 수 있다. UN을 얻은 후 RN = (N/UN) - 1로 반복 값을 계산한다.
이 작업에서 세 가지 다른 실험 프로토콜을 고려하게 된다.
1. (Fixed Parameters) 데이터 제약 DC를 고정하고 에폭과 매개변수를 변화시키면서 모델을 훈련한다. D와 N의 trade-off를 목표로 하는 allocation을 다룬다.
2. (Fixed FLOPs) 사용 가능한 계산을 고정하고 DC를 변화시킨다. 반복이 더 많은 고유 데이터를 가질 때와 비교해서 얼마나 잘 스케일되는지를 목표로 하는 return을 다룬다.
3. (Parametric Fit) 소개된 공식을 훈련 실행에 fitting 시키고, 예측 능력을 평가한다.
3.1 Parametric Fit
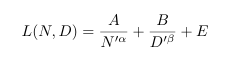


Experimental Setup
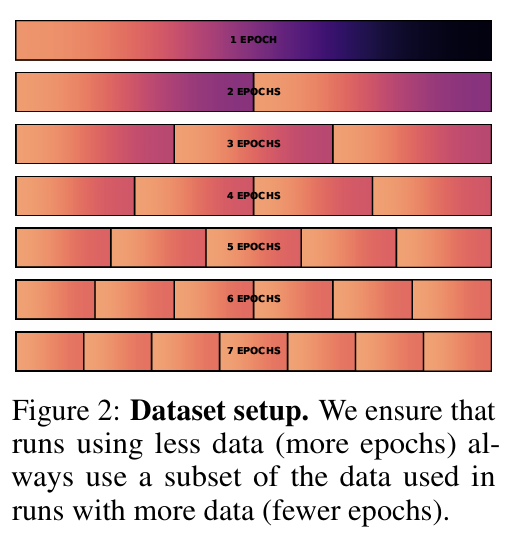
GPT-2 아키텍처와 토크나이저를 사용해서 트랜스포머 언어 모델을 훈련한다. 모델은 최대 87억 개 파라미터를 가지고 있으며, 최대 9000억 개의 총 토큰에 대해 훈련된다. 코사인 학습률을 사용하고 각 모델의 훈련 과정에서 10배 감소한다. 과적합 정도 탐구를 위해 조기 중단을 하지 않는다. 데이터 제약은 최대한 겹치도록 정의되었다. 전체 사용 가능한 데이터를 항상 반복하고, 각 epoch 후에 데이터를 섞는다. 반복 데이터로 인해 극단적인 과적합이 발생할 수 있어서, 훈련 Loss가 아닌 보류 중인 테스트 세트에서 Loss를 보고한다.
Results: Resource Allocation for Data-Constrained Scaling
모든 모델이 동일한 데이터 제약을 가진 상태에서 스케일링을 고려한다. 실험에서 고유 훈련 데이터 예산인 DC를 고정하고, 동일한 데이터 예산에서 점점 더 많은 계산을 할당받는 언어 모델을 훈련한다.

왼쪽 이미지를 먼저 보면, 100M 고유 토큰으로 스케일링하는 결과이다. 결과는 수십 개 epoch(RD > 0)과 모델 크기를 100M 토큰에 대해 계산 최적보다 20~60배 더 늘려서 훈련함으로써 50% 이상의 Loss를 줄일 수 있음을 보여준다. 이 결과를 통해서 단일 에폭 모델이 훈련 데이터를 상당히 활용하지 못하고 데이터와 매개변수를 추가함으로써 더 많은 신호를 추출할 수 있음을 보여준다.
오른쪽 이미지는 데이터 제약 스케일링 법칙에 따라 182개의 훈련 실행에 적합한 예측 윤곽을 보여준다. 단일 에폭(RD = 0)과 계산 최적 매개변수(RN = 0)의 경우, 공식들이 동일한 계산을 매개변수와 데이터에 할당하는 최적의 배분을 예측해서 효율적인 프론티어가 겹치게 된다. 데이터가 단일 에폭 이상으로 반복되는 경우에 fitting이 과잉 매개변수가 반복된 데이터보다 가치가 더 빨리 감소한다고 예측하게 된다. 결과적으로 데이터 제약 효율적 프론티어는 추가 계산을 더 많은 에폭보다는 매개변수에 할당하는 것을 제안하게 된다.
3 가지 데이터 예산 모두에서 이 결과는 epoch을 추가 매개변수보다 더 빠르게 스케일링함으로써 Allocation을 최적화하는 것을 제안하게 한다. 매개변수와 에폭을 추가하게 되면, Loss가 감소하다가 다시 증가하게 되는데, 이는 너무 많은 계산이 성능을 오히려 해칠 수 있음을 시사한다. 그렇지만, 적절한 정규화가 이러한 상태를 방지할 수 있을 것으로 본 논문은 기대하고 있다.
Results: Resource Return for Data-Constrained Scaling
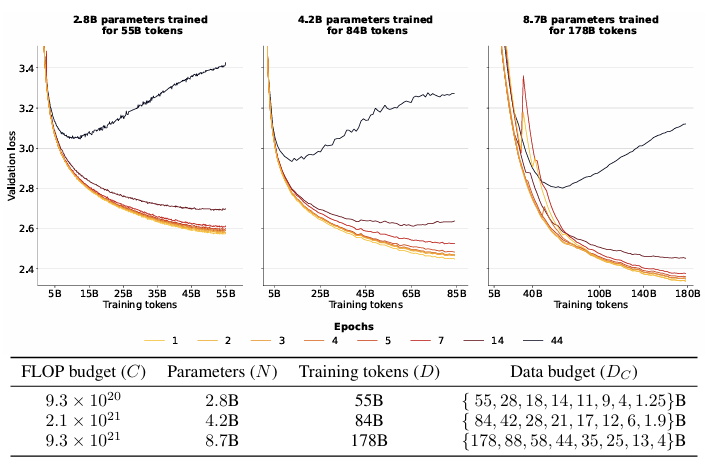
이미지를 보면, 동일한 총 토큰 수에 대해 훈련된 모델의 구성과 검증 곡선을 볼 수 있다. 반복된 데이터는 가치가 덜 하기 때문에, 고유 데이터가 적은 모델(에폭이 더 많은 모델)은 일관되게 높은 Loss를 보인다. 87억 매개변수 모델이 4 epoches 동안 훈련된 경우(DC = 44억 고유 토큰), 단일 에폭 모델(DC = 178억 고유토큰)에 비해 검증 손실이 단지 0.5% 높게 나타난다.
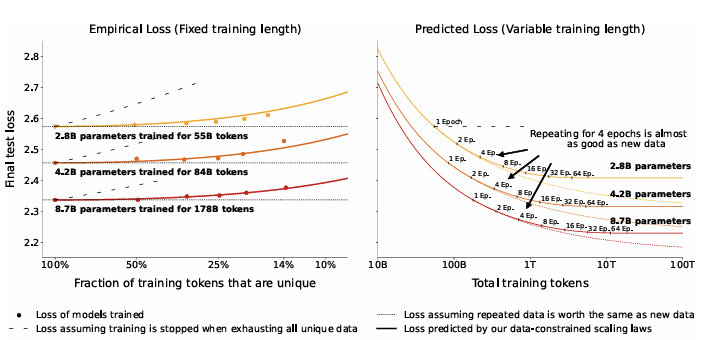
왼쪽 이미지를 먼저보면, 각 모델의 최종 테스트 Loss를 Parametric fit과 비교한다. 데이터 제약 스케일링 법칙은 반복된 데이터의 가치 감소를 정확하게 측정할 수 있음을 볼 수 있다. 하지만, 훈련 중반에 Loss가 증가하는 실패 모델의 최종 테스트 손실을 과소평가하는 경향이 있다.
오른쪽 이미지를 살펴보면, 3가지 예산을 추가로 확장해서 DC를 55B, 84B, 178B 토큰으로 유지하면서 계산을 더 확장한다. 데이터 제약 스케일링 법칙에서 RD*이 에폭의 반감기를 나타낸다. 반복된 토큰이 1/e 만큼을 잃은 지점이고, RD*이 대략 15에 해당하며, 16 epochs에 해당한다. 그래프에서는 16 epoch 근처에서 cost 감소와 수익의 평탄화를 볼 수 있다.
반복데이터를 사용해서 약 16 epoch 까지는 의미 있는 이득을 얻을 수 있으며, 그 이후에는 수익이 극도로 빠르게 감소한다.
Results: Complementary Strategies for Obtaining Additional Data
데이터를 반복하는 것이 효과적이지만, 이 방법에도 한계점이 존재한다고 한다. 그래서 본 논문은 데이터 D를 확장하는데 있어서 개선된 하류 전략을 고려한다.
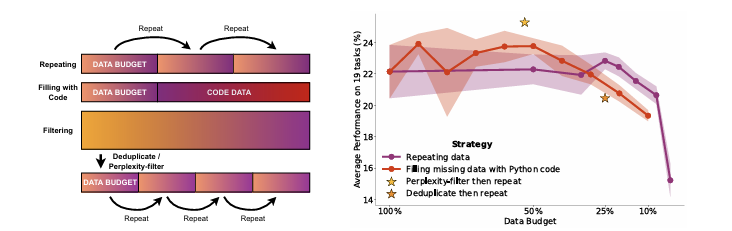
이미지의 왼쪽을 보면, 대안적인 데이터 사용 전략인 code augmentation과 Adapting filtering을 보여준다.
(a) code augmentation : stack에서 누락된 자연어 데이터를 보완하며, 코드와 자연어 샘플로 구성된 결합 데이터셋은 랜덤으로 섞인다.
(b) Adaping filtering : 중복 제거, 난해성 필터링의 일반적인 필터링 단계 성능 영향을 조사하므로써, 필터링 단계를 제거하면 추가적인 훈련 데이터를 확보할 수 있다.
반복 및 코드 채우기의 경우 DC의 일부만 사용 가능하고 나머지는 반복 or 코드 추가를 통해 보상해야 한다.
필터링의 경우 더 많은 178억 토큰으로 시작하여 노이즈가 많은 데이터를 수집하고 필터링하는 것이 더 쉽다.
난해성 필터링은 낮은 난해성을 가진 상위 25% 샘플을 선택한다.
이렇게 총 44억 토큰으로 전체 데이터 예산에 도달하기 위해 2 epoch에 가까운 반복을 사용한다.
이미지의 오른쪽을 보면, 모든 전략의 하류 성능을 비교한다. 데이터를 반복하는 경우 4 epoch까지 하류 성능 차이는 무의미하며 그 이후로 감소하기 시작한다. 데이터 50%를 코드로 채우면 자연어 작업에서의 성능 저하도 보이지 않는다. 그 이상에서는 성능이 급격히 감소한다. 추가 코드 데이터는 벤치마킹에서 고려되지 않은 비자연어 작업에 도움이 될 수 있다.
필터링 접근 방식 중에는 난해성 필터링이 효과적인 반면 중복 제거는 도움이 되지 않는다고 한다. 데이터 제약 상황에서는 노이즈가 많은 데이터셋에 필터링을 예약하고 code augmentation과 반복을 사용해서 데이터 토큰을 늘리는 것이 좋다.
Conclusion
데이터 제약 조건 하에서의 스케일링을 다루며, 고유 데이터가 제한된 경우 계산 자원을 최적으로 사용하는 방법에 초점을 맞춘 연구이다. 본 논문은 반복된 데이터의 가치 감소를 고려한 Chinchilla 스케일링 법칙의 확장을 제안하고, 제어된 실험 세트를 사용하여 기능을 적합시켰다.
논문을 통해 데이터를 반복하여 대규모 언어 모델을 여러 에폭 동안 훈련시키는 것이 유익하다는 것과 스케일링 법칙이 여러 epoch 체제에서도 지속됨을 알 수 있다.
논문을 리딩하기 전 스케일링의 컨셉이 잘 이해가 되지 않았다. 데이터 제약이 빅데이터 시기에도 일어날 수 있는 것인가를 초반에는 생각해보았지만, LLM이 얼마나 많은 데이터를 벌써 받아들였기에 데이터 제약 상황을 벌써 우리가 고민해야 하는지 다시 생각해볼 수 있는 논문이었다고 생각한다. 그리고 데이터의 반복에도 최적점이 있다는 것에 놀라웠다.
728x90'LLM papers' 카테고리의 다른 글
