-
Transformer NetworksGoogle ML Bootcamp/Sequence Models 2023. 10. 4. 20:12728x90
※ Self Attention

- q : query
- K : key
- V : value
- 이 벡터들은 각 단어에 대한 Attention 값을 계산하기 위한 핵심 input이다.

- q<3> = W^Q * x<3>
- K<3> = W^K * x<3>
- V<3> = W^V * x<3>
- q<3>을 다른 자리에 있는 단어들과의 상관관계를 인식 시키기 위해 q<3> * K<1>, ..., q<3> * K<5>의 형태로 만들어 벡터화시킨다. 이렇게 모든 단어를 연결하여 문장의 의미로 인식되게 만든다.
- 5개의 단어로 표현 될 수 있는 문장에서 A<3> 단어를 표현하기 위해서 V<1>, ..., V<5> 와 q<3> * K<1>, ... q<3> * K<5>를 각각 곱하고 전의 모든 값들을 합한다. 이렇게 A<1> ~ A<5>의 모든 단어를 표현할 수 있다.
- softmax 함수의 분모 d_k^(1/2)는 내적의 크기를 조정해 폭주하지 않게 한다.
※ Multi-Head Attention

- 현재 Attention(~~) 함수는 W1으로 첫 번째 Head에 대한 Attention을 계산한 것이다.
- W1에 대한 질문이 what's happening? 이라면 가장 연관 있는 것은 visite 일 것이고, W2에 대한 질문에 when? 이라면 가장 연관 있는 것은 septembre 일 것이다. W3에 대한 질문이 who? 라면 가장 연관 있는 것은 Jane 일 것이다. 이렇게 질문에 대해 가장 연관있는 것을 highlight로 가지면서 다중 Attention을 만든다.
- heads 각각이 다른 특징들이라고 생각하면 되는데, 이러한 특징을 신경망으로 전달하면 아주 풍부한 문장 표현을 계산할 수 있다. -> 결국 최종 값은 이러한 모든 heads의 연속이다.
- 이러한 모든 반복을 for loop로 구현하기 보다는 실제로 각 heads의 값을 병렬적으로 계산한다. 왜냐하면 어느 것도 다른 head의 값에 의존하지 않기 때문이다.
※ Transformer Network
- Transformer가 Network에 더 잘 작동할 수 있도록 하는 추가 기능 :
입력의 위치 인코딩 : sin과 cos 방정식을 조합하여 사용한다.

-> pos는 현재 위치, i는 pos 안에서 index
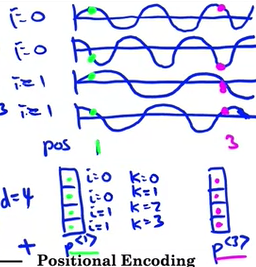
- 이러한 과정을 따라서 p<1>과 p<3>가 다르다는 것을 인식할 수 있다.

- Masked Multi-Head Attention은 올바른 번역 데이터 세트를 사용하여 Transfomer를 훈련시키는 훈련 과정에서만 중요하다. 문장의 마지막 부분을 차단하고 테스트 시나 예측 중에 네트워크가 수행해야 하는 작업을 모방한다. 처음 몇 단어만 반복해서 네트워크가 완벽하게 번역된 것처럼 가장하고 나머지 단어를 숨겨서 번역이 완벽한지, 새 네트워크가 시퀀스의 다음 단어를 정확하게 예측할 수 있는지 확인하는 것이다.
- Multi-Head Attention을 Feed Forward Neural Network로 보내는 것이 인코더, 디코더도 같은 방식을 취하고 있지만, Masked Multi-Head Attention을 추가하고 모든 과정에 Add & Norm을 추가한다. 마지막으로 Softmax와 Linear로 Output을 출력하는 단계로 Transfomer가 구성된다.
728x90'Google ML Bootcamp > Sequence Models' 카테고리의 다른 글
Various Sequence To Sequence Architectures (0) 2023.10.03 Learning Word Embeddings: Word2vec & GloVe (0) 2023.10.02 Word Embeddings (1) 2023.10.01 Recurrent Neural Networks (0) 2023.09.29