-
Are Emergent Abilities of Large Language Models a Mirage?LLM papers 2024. 3. 20. 22:49728x90
[2304.15004] Are Emergent Abilities of Large Language Models a Mirage? (arxiv.org)
Are Emergent Abilities of Large Language Models a Mirage?
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly
arxiv.org
Abstract
최근 연구에서는 대규모 모델에서만 나타나는 'Emergent Abilities'를 보여준다고 주장한다.
창발 능력이 흥미로운 이유
1. 나타나지 않다가 갑자기 나타나는 뚜렷한 전환을 보인다는 것
2. 예측할 수 없는 규모에서 발생한다는 것
하지만, 본 논문에서는 창발에 대한 조금 다른 시각을 제시한다.
특정 작업과 모델 패밀리에 대해 고정된 모델 출력을 분석할 때, 창발이 모델의 규모에 따른 본질적인 변화 때문이 아니라는 것인데, 순수하게 연구자가 선택한 metric 기준 때문에 나타나는 것으로 보는 것이다. 특히 비선형적이거나 불연속적인 측정 기준이 창발을 나타나게 하고, 선형적이거나 연속적인 측정 기준은 예측 가능한 변화 정도를 생성하게 된다고 보고 있다.
총 3가지의 보완적인 방법으로 테스트를 실시한다.
(1) InstructGPT/GPT3를 사용한 작업에서 metric 기준 선택의 효과에 대한 세 가지 예측을 제시, 테스트, 확인
(2) BIG-Bench에서 주장된 창발 능력에 대한 메타 분석을 통해 metric 기준 선택에 대한 두 가지 예측을 제시, 테스트, 확인
(3) 다양한 Deep Network에서 여러 Vision task에 대해 이전에 볼 수 없었던, 창발하는 것처럼 보이는 능력을 생성하기 위해 평가를 위한 metric 기준을 의도적으로 변경하는 방법
3가지 분석을 통해서, 본 논문은 주장된 창발 능력이 다른 metric 기준이나 더 나은 통계를 사용할 때 사라지며, AI 모델의 규모 확장의 근본적 속성이 아니라는 증거를 제시하게 된다.
1. Introduction
창발의 개념은 시스템의 복잡성이 증가함에 따라 시스템의 미시적 세부사항을 정확히 양적으로 이해한다고 해도 예측할 수 없는 새로운 속성이 나타난다고 "More Is Different"에서 대중화되었다. 이 속성이 GPT, PaLM, LaMDA와 같은 LLM에서 발생한다는 관찰로 인해서 큰 관심을 받고 있다.

LLM의 창발 능력 "emergent abilities of LLMs"는 최근 소규모 모델에서는 나타나지 않지만, 대규모 모델에서는 나타나는 능력으로 단순히 소규모 모델의 성능 개선을 extrapolating(외삽)해서 예측할 수 없는 능력으로 명확히 정의되었다.
최초로 GPT3 family 에서 발견되었는데, 이후 연구에서 "모델 성능이 일반적 수준에서 예측 가능하지만, 특정 작업의 성능이 때때로는 예측할 수 없이 갑작스럽게 규모에 따라 나타날 수 있다"고 강조하게 된다.
이러한 여러 정의와 강조들을 통해서 LLMs에서 창발은 두가지 정의적 속성을 가진다.
1. Sharpness : 나타나지 않다가 갑자기 나타나는 것처럼 보임
2. Unpredictability : 예측할 수 없는 모델 규모에서의 전환
이러한 창발에 대해서 의문점이 제기 될 수 있게 된다.
- 어떤 능력이 나타날지 제어하는 것은 무엇인가?
- 능력이 언제 나타날지를 제어하는 것은 무엇인가?
- 바람직하지 않은 능력은 절대 나타나지 않고, 바람직한 능력은 더 빨리 나타나게 할 수는 없을까?
결국 창발 자체가 큰 모델이 언젠가는 경고 없이 위험한 능력을 습득할 수 있다는 것이기 때문에 이러한 의문점들이 제기되는 것이다.
본 논문에서는 LLM이 창발 능력을 가지고 있다는 주장에 대해서 의문점을 제기한다.
- 왜 창발 능력이 비선형적이거나 불연속적으로 모델의 토큰 당 오류율을 조정하는 metric에서만 나타나는 것처럼 보일까?

BIG-Bench 에서의 창발 능력 92%가 이러한 두 가지 metric 기준에서만 나타난다고 한다.
그렇다면 Sharpness와 Unpredictability가 모델의 토큰 당 오류율이 증가하는 규모에 따라 부드럽고 연속적이며 예측 가능하게 변화함에도 불구하고, 연구자가 metric을 선택함으로써 유도할 수 있는 것이 아닐까? 라는 것이다.
본 논문에서의 대안은 창발 능력이 연구자가 토큰 당 오류율을 비선형적으로, 불연속적으로 변형하는 metric 기준을 선택함으로써, 그리고 더 작은 모델의 성능을 정확하게 추정하기 위한 충분한 test data를 가지고 있지 않아 더 작은 모델이 작업을 전혀 수행할 수 없는 것처럼 보이게 함으로써 유발된다고 가정한다.

결국 이 시각자료를 보면, Nonlinear하거나 Discontinuous 한 경우에는 그래프가 확 올라가면서 창발이 발생하지만, Linear하거나 Continuous한 경우에는 scale이 커지더라도 기울기는 감소하면서 창발이 발생하지 않았다는 것이 확인된다.
이를 통해, 본 논문에서는 LLM에서 창발 능력이 연구자의 metric 선정에 따른 것이지 모델 크기로 인한 예측불가능한 변화가 아니라고 판단한다.
이제 앞서 말했던 총 3가지 테스트를 진행하면서 주장에 대한 근거를 제시한다.
2. Alternative Explanation for Emergent Abilities

per-token cross entropy as a function of number of parameters N 
p is unknuwn, one-hot distribution of the observer token v* 
N parameters then has a per-token probability of selecting the correct token 
If the probability each token is correct is independent, the probability of scoring 1 
본 논문에서는 위에 설명된 수식들을 통해서 크기의 증가에 따른 sharp and unpredictable의 변화가 세 가지 요인에 의해서 설명될 수 있다고 정리하고 있다.
(1) 연구자가 토큰 당 오류율을 비선형적이거나 불연속적으로 조정하는 metric 기준을 선택
(2) 작은 매개변수 체제에서 모델 성능을 추정하기에 충분한 resolution이 없는 경우
(3) 더 큰 매개변수 체제를 충분히 샘플링하지 못하는 경우
이 부분에서 Token Edit Distance(N)은 모델이 올바른 토큰을 선택하는 확률에 따라 모델의 성능을 측정하는 데 사용되는 선형 metric 이다. 이 metric을 통해 모델 성능의 변화를 smooth하고 continuous, predictable 하게 보여줄 수 있기 때문에 창발 능력이 특정 metric 기준에 따라 나타나거나 사라질 수 있으며, 이러한 metric 기준의 선택으로 창발 능력을 조정할 수 있다는 논문의 주장이 어느정도 타당성이 있다고 생각할 수 있다.
3. Analyzing InstructGPT/GPT-3’s Emergent Arithmetic Abilities
GPT family를 선택한 이유는 이전 논문들에서 integer arithmetic tasks에서 GPT가 창발 능력을 보인다고 주장했으며, 공개적인 쿼리가 가능하기 때문이다.
본 논문은 앞서 2장에서 설명했다시피 3장에서도 3가지의 예측 사항에 대해 강조하고 있다.
1. 비선형 또는 불연속적인 metric 기준에서 선형 또는 연속적인 metric 기준으로 변경하면, 모델 규모에 따른 smooth, continuous, predictable 한 성능 개선이 드러나야 한다.
2. 비선형 metric 기준인 경우, test datset 크기를 늘려 모델 성능의 resolution을 증가시키면, 선택된 metric 기준의 예측 가능한 비선형 효과와 일치하는 부드러운 연속적이고 예측가능한 모델 개선이 나타나야 한다.
3. metric 기준에 관계없이, 대상 문자열 길이가 증가함에 따라 모델의 성능이 length-1 target performance에 대한 성능 함수로 예측 가능하게 영향을 받아야 한다. 정확도는 기하 급수적으로, Token Edit Distance의 경우는 quasilinearly하게 감소해야 한다.
그렇다면 이제 예측 사항들을 살펴보자.
Prediction 1 : Emergent Abilities Disappear With Different Metrics

이 시각자료를 보면 상단 3개의 경우 metric 기준이 Accuracy이다. 이때, GPT family는 target strlen이 4 or 5자리인 경우 창발능력을 보이고 있다. 하지만, 비선형인 Accuracy에서 선형인 Token Edit Distance로 metric을 변경하게 되면, 모델 규모가 증가함에 따라 부드럽고 연속적이며 예측 가능하게 개선되는 그래프의 모양을 볼 수 있다. 또한, Token Edit Distance에서 target strlen이 1에서 5로 증가함에 따라 family의 성능이 대략 quaslinearly하게 감소하는 것도 관찰할 수 있다.
Prediction 2 : Emergent Abilities Disappear With Better Statistics

이제 이 시각자료를 보면, 비선형 metric 기준인 Accuracy에서도 더 작은 모델들이 0이 아닌 Accuracy를 가지는 것을 볼 수 있으며, 모델 정확도를 측정하기 위해 추가 test data를 생성함으로써 resolution을 증가시킨 상태에서 InstructGPT/GPT3 family의 모든 모델이 기회 수준 이상의 정확도를 달성한다는 것을 볼 수 있었다. 또한, target strlen 길이가 증가함에 따라 정확도가 기하급수적으로 감소하는 것도 관찰할 수 있었다.
4. Meta-Analysis of Claimed Emergent Abilities
GPT family를 분석하는 것은 모델이 공개적으로 쿼리가 가능하기 때문이다. 하지만, 다른 모델 패밀리는 공개적으로 쿼리가 가능하지 않다. 그 때문에 본 논문에서는 또다른 예측 2가지를 제안한다.
Prediction 1 : Emergent Abilities Should Appear with Metrics, not Task-Model Families
창발이 실제로 일어난 경우, 어떠한 합리적인 측정 기준에서도 task-model family 쌍이 창발을 보여야 한다. 하지만, 본 논문의 주장이 옳다면 창발이 특정 metric 기준에서만 나타날 것이다. 이를 테스트하기 위해, 본 논문은 창발이 나타나는 metric 기준을 분석하게 되는데, task-metric-model family 삼중항에서 가능한 창발을 결정하기 위해 Emergence Score를 아래와 같이 정의한다.


시각자료를 살펴보면 BIC-Bench의 39개 선호 측정 기준 중 최대 5개만이 창발을 보인다는 것을 발견했다. 5개의 metric에는 비선형이거나 불연속적인 것들도 있다. 이를 통해, 모델 출력이 다른 metric 기준으로 평가될 때는 창발이 발생하지 않는다는 것을 증명할 수 있다. 또한, 수작업으로 주석을 달았던 task-metric-model family 삼중항을 분석한 결과에서는 2개의 metric 기준이 창발의 92% 이상을 차지한다는 것을 증명했다.
Prediction 2 : Changing Metric Removes Emergent Abilities
해당 예측을 테스트하기 위해, 본 논문에서는 LaMDA family에 초점을 맞추었다. LaMDA family는 BIG-Bench를 통해 이용가능하기 때문.
본 논문의 테스트에서는 LaMDA가 다중 선택 등급에서 창발을 보이는 task를 식별한 다음, LaMDA가 동일한 작업에서 다른 BIG-Bench metric 기준인 Brier score에서도 여전히 창발을 보이는지를 확인한다.
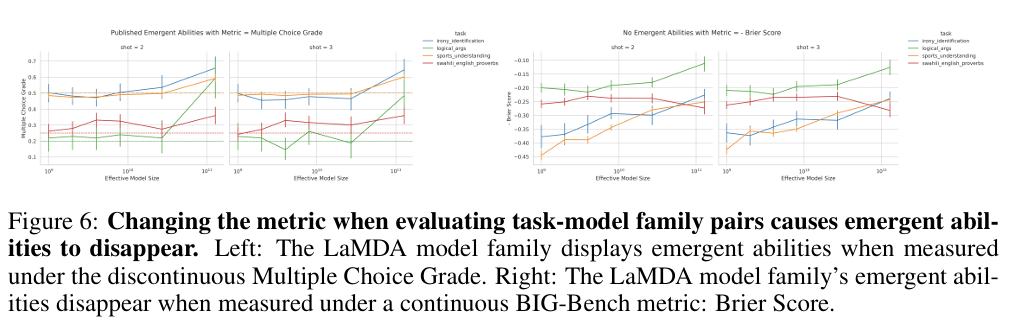
시각 자료를 확인해보면, LaMDA의 창발은 불연속적인 다중선택등급에서 측정될 때 나타나지만, 연속적인 Brier score로 metric 기준을 변경했을 때는 사라진다. 이러한 결과를 통해 창발이 선택된 metric 기준에 의해 유발될 수 있음을 다시 한번 지지하게 된다.
5. Inducing Emergent Abilities in Networks on Vision Tasks
마지막으로 다양한 아키텍쳐를 가진 심층 네트워크에서 여러 Vision Tasks에 대해 창발을 유도한다. Vision Tasks에서는 갑작스러운 변화가 잘 관찰되지 않기 때문이라고 한다.
Emergent Reconstruction of CIFAR100 Natural Images by Nonlinear Autoencoders
본 논문은 CIFAR100 natural images에 대해 훈련된 shallow nonlinear autoencoders에서 이미지 재구성 능력을 출현을 유발한다. metric의 sharpness가 창발에 대한 책임을 강조하고, 정확도를 넘어 다른 metric에도 확장될 수 있음을 보여주고자, reconstruction이라는 metric을 정의한다.

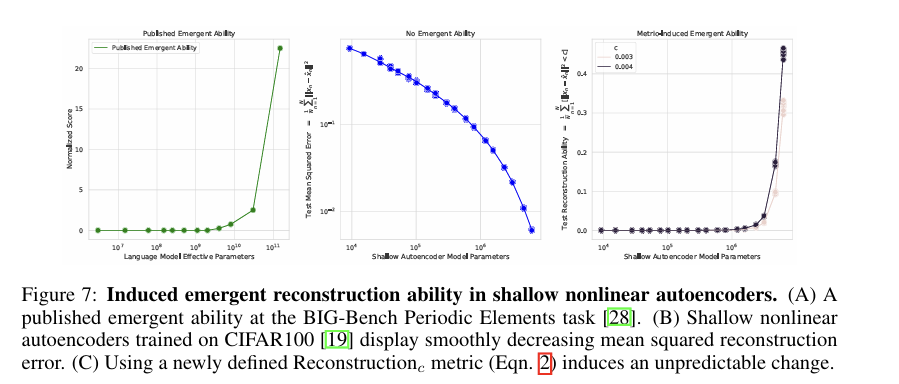
시각자료와 함께 살펴보면 좋은데, 두번째 그림을 보면, Autoencoder family는 model parameter가 증가함에 따라, mean square error가 shallow하게 감소하게 된다. 또한, 세번째 그림을 보게 되면, 해당 metric에서 특정 c 선택에 대해 오토인코더 family는 갑작스럽고 예측할 수 없는 이미지 재구성 능력을 발휘하게 된다. 이는 Published 되었던 창발 능력인 첫번째 그림과 동일한 결과를 보여주게 된다.
Emergent Classification of Omniglot Characters by Autoregressive Transformers
마지막으로, 논문에서는 Omniglot hand-written 문자를 autoregressively classify 하기 위해 훈련된 transformers에서 창발 능력을 유발한다. Omniglot 이미지는 convolutional layer에 의해 임베딩되고, 임베딩 된 image-image class label 쌍의 시퀀스가 decoder-only transformers에 입력된다. 여기서 L ∈ [1, 5]의 시퀀스에서 이미지 분류 성능을 다시 하위 정확도를 통해 측정하고, 모든 L 이미지가 올바르게 분류되면 1, 아니면 0을 출력한다고 한다.

시각자료를 살펴보면, 세 번째 그림에서 transformer가 Omniglot hand-written 문자를 올바르게 분류하는 것으로 보이는 창발을 보여주고, 이는 Published 된 창발능력인 첫 번째 그림과 어느정도 일치하는 모습을 보여준다.
6. Discussion
본 논문은 LLMs에서 주장된 창발 능력에 대한 대안적 설명을 제시하고 있다. 여러가지 테스트들을 통해서 고정된 작업과 모델 패밀리에 대해, 연구자가 metric을 선택함으로써 창발을 생성하거나 없애는 것이 가능하다는 것을 보여주었다. 창발은 특정 작업에서 모델 패밀리의 근본적 속성 보다는 연구자의 선택에 의해 만들어진 것이라고 생각할 수 있다. 이 논문은 이전에 주장된 창발 능력이 연구자 분석에 의해 유발된 환영일 가능성이 높음을 시사한다.
2024.3 에 있었던 Langcon에서 제일 처음 창발에 대한 이야기를 접할 수 있었다. 아니나 다를까 NeurlPS2023의 따끈따끈한 최신 논문이었고, award를 수상한 논문인 만큼 충분히 생각해볼 법한 주제를 다루고 있었다. LLM에서 일어나는 창발이 데이터가 많아서였을지, 아니면 hallucination 이었을지 정도로 생각을 해보고 있었는데, 본 논문의 테스트 들을 통해서 창발은 연구자가 생성할 수도 없앨 수도 있는 존재였을 수도 있겠다는 생각의 전환점을 느끼게 되었다.
728x90'LLM papers' 카테고리의 다른 글
Scaling Data-Constrained Language Models 논문 리뷰 (0) 2024.05.11 QLoRA: Efficient Finetuning of Quantized LLMs 논문 리뷰 (0) 2024.05.04 ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings 논문 리뷰 (0) 2024.04.28 Toolformer: Language Models Can Teach Themselves to Use Tools 논문 리뷰 (0) 2024.04.02 Jailbroken: How Does LLM Safety Training Fail? 논문 리뷰 (0) 2024.03.27