-
Evaluating ModelsAI for Medicine(coursera)/Evaluating Models 2023. 12. 28. 10:38728x90
※ Sensitivity, Specificity and Evaluation Metrics


- Sensitivity : 환자가 질병에 걸렸다는 점을 감안하여 해당 환자를 해당 질병에 걸린 것으로 분류할 확률
- Specificity : 환자가 정상인 경우 환자를 정상으로 분류할 확률
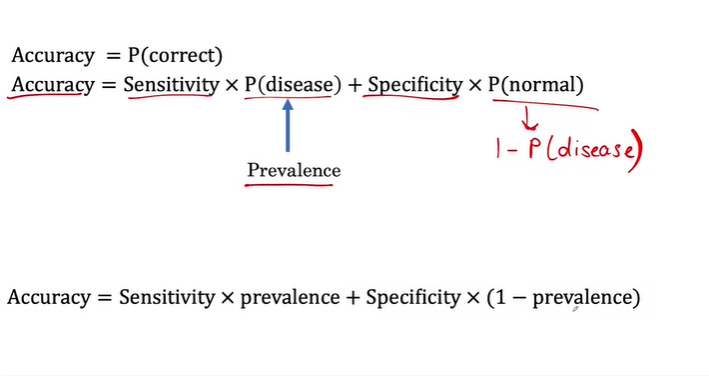
- P(disease) = Prevalence
- P(normal) = 1 - P(disease) = 1 - Prevalence
※ PPV, NPV

- PPV = P(disease | +) : Model이 환자의 양성을 예측했을 때, 환자가 실제로 질병에 걸릴 확률
- NPV = P(normal | -) : Model이 환자의 음성을 예측했을 때, 환자가 실제로 정상일 확률
- 이 예시에서 PPV = 2 / 4, NPV = 5 / 6이 된다.

- PPV = TP / (TP + FP)
- NPV = TN / (TN + FN)
- Sensitivity = TP / (TP + FN)
- Speciticity = TN / (FP + TN)
평가지표로는 threshold를 지정하고 주로 ROC curve를 사용한다.
※ Confidence Interval
실제로는 많은 표본에 대한 신뢰 구간을 계산하지 않고, 한 샘플에 대해서만 모델 성능을 계산한다. 표본의 경우 계산된 신뢰 구간에 p가 포함될 수도 있고, 포함되지 않을 수도 있지만, 95% 신뢰구간에 p가 속해있다면 p가 포함된다고 95% 확신할 수 있다.

신뢰구간의 너비에 영향을 미치는 요인 중 하나는 표본의 크기이다. 신뢰구간의 폭은 두 숫자가 얼마나 가까운지에 따라 결정되는데, 위 사진과 같이 n=100과 n=500의 경우를 비교해보자. 수치가 이전 표본의 5배 늘어나게 되면, 신뢰구간은 더 좁아지게 된다. 표본이 커질 수록 모집단 두 숫자가 더 가깝기 때문에 모집단 정확도가 더 잘 추정될 수 있을 것으로 기대할 수 있다는 것이다.
전체 모집단에 대해 모델을 실행할 수 없는 경우에도 최소한 표본에 대한 테스트 결과를 사용하여 모집단 정확도가 있다고 확신하는 범위를 표현할 수 있기 때문에, 신뢰 구간은 유용하게 사용될 수 있다.
728x90