-
Detection AlgorithmsGoogle ML Bootcamp/Convolutional Neural Networks 2023. 9. 25. 21:59728x90
※ Landmark detection

- 얼굴 사진의 왼쪽 눈을 기준으로 할 경우 그 지점이 (x, y)가 된다.
- 사진이 ConvNet을 통과할 때 특정 세트를 가지게 할 것이고, 64개의 landmark가 있으면 l1x, l1y, ... l64x, l64y, face 인지 아닌지 까지 총 129개의 출력 유닛을 가진다.
- 얼굴 자체 뿐만 아니라 얼굴에서의 랜드마크들을 모두 가르쳐 줄 수 있다.
- 얼굴에서 감정을 인식하는 기본 구성가 되고 snapchat 사진 같은 AR 증강현실 필터도 얼굴에 특수 효과를 가져 올 수 있음.
- 포즈에 관심이 있다면 랜드 마크를 어깨, 팔, 다리 등으로 지정해서 ConvNet을 통과시키면 된다.
※ Object detection

- sliding window object detection을 이용해서 객체 탐지
- 특정 크기 window를 설정하고, ConvNet에 작은 직사각형 영역을 입력 -> 어떤 결과 출력
- 그 결과를 또 ConvNet에 입력하고 window를 계속 이동시키면서 ConvNet에 입력 -> 0 or 1로 결과 출력 하면서모든 이미지를 조사 -> 어떤 사물이 있는지를 인식하게 됨.
- Stride를 아주 큰 사이즈로 사용한다면 ConvNet을 통과하는데 필요한 윈도우 수를 줄일 수 있음 but 거친 입도로 성능 저하
- Stride를 아주 작은 사이즈로 사용한다면 ConvNet을 통과하는데 아주 많은 비용이 듦.
- 실제로는 매우 고운 입성도매우 작은 Stride를 사용하지 않는 한, 이미지 내에서 정확하게 객체 위치를 감지하기는 불가능함.
※ Convolutional Implementation of Sliding Windows
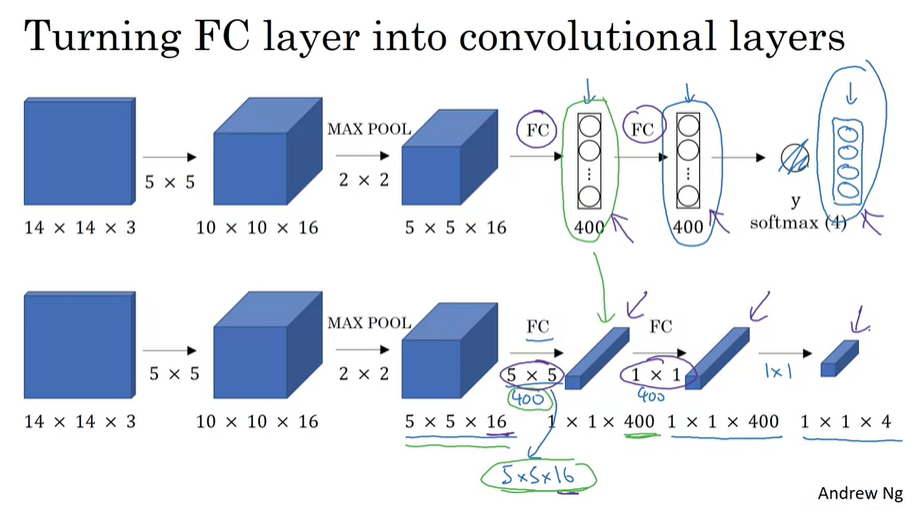


- 초기 window를 14*14로 잡았을 경우 ConvNet을 통과시키면서 detection을 하게 되면 훨씬 효율적인 cost로 sliding window를 적용시키고 이미지를 인식할 수 있다.
- 경계 상자의 위치가 정확하지 않다는 문제점이 있음.
※ Bounding Box Predictions

- 정확하게 Box가 Bound를 그리지 못한다는 단점을 보완하는 알고리즘으로 YOLO Algorithm이 있음.
- YOLO Algorithm은 bx, by, bh, bw로 정확한 Box를 출력할 수 있다는 장점이 있음.
- 테스트 시 Input image x를 제공하고, Ouput y를 얻을 때까지 순전파를 실행해야 한다.
- bx, by, bh, bw는 object 경계 상자, 맨 위의 0과 1은 관련된 객체가 있는지, 아래 0과 1들은 어떤 객체인지
- 셀 내에 1개의 객체를 가질 경우 매우 잘 작동함.
- 객체의 중간 점을 보고 객체의 중간 점을 포함하는 격자판 셀 하나에 해당 객체를 할당하는 방법임.
- 같은 격자판 안에 객체의 중간 점이 두 개가 될 확률을 최대한 낮춰야 한다.

0 <= bx + by <= 1
bh + bw > 1
※ Intersection Over Union

- IOU : 합집합에 대한 교집합
- IOU가 0.5 이상이면 답안은 옳은 것으로 간주됨. 완전히 겹치면 IOU = 1
- IOU가 높을수록 경계상자가 거의 겹쳐짐.
※ Non-max Suppression

※ Anchor Boxes

- (grid cell, anchor box) : 이런식으로 쌍으로 존재 -> 대상 라벨에 해당 객체가 인코딩 되는 방법
- 중간 점이 아닌 highest IOU의 grid cell과 중간 점을 모두 기준으로 삼는다.

※ Semantic Segmentation with U-Net

- Object detection 알고리즘에서는 Bounding Box를 그리게 된다.
- 이 Bounding Box 안의 모든 픽셀이 무엇인지를 알고 싶다면 Semantic Segmentation을 이용하면 된다.

- Segmenation을 통해서 불규칙성을 더 쉽게 인식하고 심각한 질병 진단과 수술 계획 수립에 도움을 줄 수 있음.

- Segmenation을 이용해서 pixel 단위로 표현한 Segmentation Map

- 기존 신경망의 경우 왼쪽에서 오른쪽으로 갈수록 dimension을 작아진다. 하지만, 점차 출력을 위해 크기를 확대해야 함.
- 단위에 대해서 깊이 알게 될 수록 높이와 부피는 다시 높아지고 채널 수는 줄어들기 때문에 Segmentation Map을 얻기 전까지 계속해서 dimension이 확장되어야 한다.
※ Transpose Convolutions

- 2*2 -> 4*4로 만들기 위해서 filter를 3*3을 사용하고, 4*4에 padding=1로 padding을 해서 6*6을 만들어준다.
- padding 영역에는 아무것도 적으면 안 되기 때문에 해당 범위를 무시하고 진행한다.
- 2를 해당 범위에 모두 곱한다.
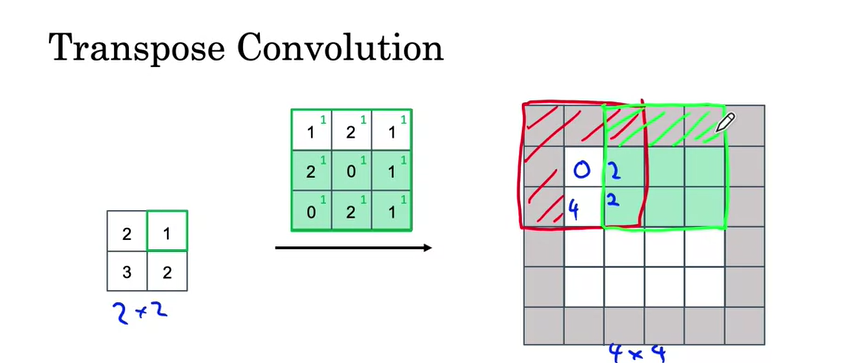
- stride = 2인 경우 빨간색과 초록색이 겹치는 부분은 두 개의 값을 더한다.
- 1을 초록색 모든 범위에 곱한다.
※ U-Net

- 매우 적은 수의 학습 데이터로도 정확한 Image Segmentation 성능을 보여준다.
- 인코딩 단계에서 dimension이 줄어들고, 디코딩 단계에서 저차원의 정보만을 이용하다보니 생기는 정보 손실 문제를 해결
- 저차원 뿐만 아니라 고차원 정보도 이용하여 이미지의 특징을 추출하고 정확하게 위치를 파악!!!!
- skip connection을 통해서 인코딩 레이어와 디코딩 레이어를 직접 연결
- 인코더와 디코더를 연결하는 브릿지를 U 곡선 제일 하단에 위치시킨다.
- 디코딩 시 Transpose Convolution을 통해서 Map 차원을 늘리면서 채널 수는 반으로 줄인다.
- skip connection 시킨 고차원 정보와 줄어든 저차원 정보 두 개의 Map을 concatenation을 통해서 합치고 저차원 이미지 정보와 고차원 정보를 모두 이용할 수 있게 한다.
728x90'Google ML Bootcamp > Convolutional Neural Networks' 카테고리의 다른 글
Face recognition & Neural Style Transfer (0) 2023.09.27 Case Studies & ConvNet practical Advice (0) 2023.09.24 Convolutional Neural Networks (0) 2023.09.23