-
Optimization AlgorithmsGoogle ML Bootcamp/Improving Deep Neural Network 2023. 9. 12. 16:17728x90
※ Mini-batch Gradient Descent

- 1000개의 mini-batch를 통해서 1 epoch을 실시한 상황.
- 여러개의 epoch을 실시하고 싶다면 for loop 하나를 추가해야함.
※ Understanding Mini-batch Gradient Descent

- batch에서는 cost function이 하강함, mini-batch 에서는 반드시 cost function이 하강하지 않을 수도 있다.
- 장점 1 : 미니배치 크기가 1000개의 예시일 때, 1000개의 예시로 벡터화가 가능할 것이다. 이 경우 예시를 하나씩 처리하는 것보 훨씬 빠르다.
- 장점 2 : 전체 훈련 세트를 처리할 때 기다릴 필요없이 진전이 있도록 할 수 있다.
- mini-batch를 사용하면 연속 하강보다는 조금 더 균등하게 최솟값을 향해 가는 경향이 있다. 하지만 항상 정확하게 변환되거나 작은 범위에서 진동하는 것은 아니다. -> 학습 속도를 느리게 만드는 방법을 사용해서 문제를 개선할 수 있다.
- small training set : batch gradient descent를 사용
- bigger training set : mini-batch gradient descent를 사용 -> 64, 128, 256, 512, 1024 이렇게 2의 제곱승으로 사용하는 것이 좋다.
- mini-batch의 x(t), y(t)가 CPU/GPU의 메모리로 모두 들어가게 해서 사용한다.
※ Understanding Exmponentially Weighted Averages
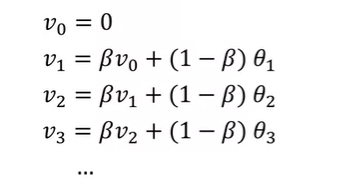
- 일반화 식 : V(theta) = beta * V(theta) + (1 - beta) * theta(t)
※ Gradient Descent with Momentum

- Momentum 알고리즘
- 경사 하강 속도를 높일 수 있음.
- 기울기 하강, 미니 배치 기울기 하강에서 변동을 무디게 하는 효과가 있음.
- bias 최적화에 대한 내용을 거의 볼 수 없다. beta가 0.9이므로 거의 티가 나지 않는다.
- (1 - beta)가 삭제 되어서 사용되는 경우도 많다.
※ RMSprop
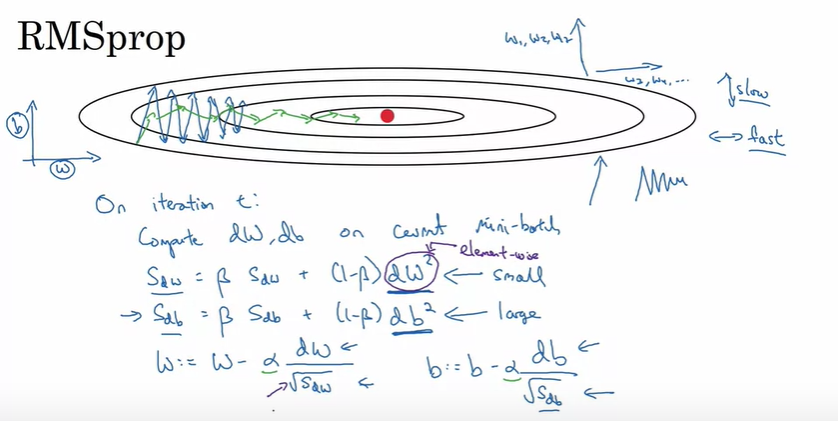
- 미분이 매우 큰 db와 상대적으로 작은 dw로 이루어진다. 수평방향보다 함수가 b 방향인 수직방향으로 훨씬 더 가파르게 기울어져 있기 때문. -> db^2은 매우 큰 값
- 수직 방향의 업데이트가 매우 큰 숫자로 이루어져서 진동을 완화하는데 도움이 된다.
- 수직 방향으로 발산하지 않고 더 빠른 학습을 얻을 수 있다는 장점이 있다.
- 기울기 하강, 미니 배치 기울기 하강에서 변동을 무디게 하는 효과가 있음.
- 더 큰 학습률을 사용할 수도 있음. -> 알고리즘의 효과를 높일 수 있음.
※ Adam Optimization Algorithm

- 마지막 w와 b가 Adam을 사용한 것

- Adam 기법 : Adapt moment estimation
- beta1 -> 미분의 평균값 계산(1차 모멘트)
- beta2 -> 제곱의 지수 가중 평균 계산(2차 모멘트)
728x90'Google ML Bootcamp > Improving Deep Neural Network' 카테고리의 다른 글
Regularization & Optimization (0) 2023.09.10