-
cs231n 2강 - Image Classificationcs231n 정리 2023. 3. 19. 14:29728x90
※ Image Classification 이란?
- A core task in Computer Vision
- 이미지가 어떤 카테고리에 속할까? 라는 질문을 가지고 클래스를 분류하는 작업
- Detection, Segmentation, Image Captioning 등의 기술들이 분류 이후에 사용된다.
★ Image Classification의 어려움
- 사람이 보는 이미지 vs 컴퓨터가 보는 이미지에 차이가 있다.
- 사람이 보는 이미지는 그림 그 자체이지만, 컴퓨터는 [0, 255] 사이의 숫자로 이루어진다.
- 보는 시야, 조명, 변형, 은폐, 은닉, 배경과 거의 구분이 힘든 상태, 같은 class 내에서의 구분 등이 존재한다.
★ 알고리즘
1. 화살표를 이용해 "Feature를 이용한 규칙 찾는법" : 알고리즘 확장성 ↓, 다른 이미지 적용 ↓

cs231n 2강 ppt 2. Data-Driven Approach(데이터 중심 접근 방식)
- 이미지와 라벨의 데이터를 모은다.
- 머신러닝을 사용하여 훈련시킨다.
- 새로운 이미지에 훈련 상태를 평가한다.

※ Nearest Neighbor(NN)
- L1 distance( |test-train| 값의 총합 )
- train과 predict 함수를 사용
- train : O(1), predict : O(N) -> NN 모델의 문제

cs231n 2강 ppt ■ train 함수 : Memorize training data
■ predict 함수 : For each test image : Find closest train image, Predict label of nearest image
★ NN 모델의 문제점은?
- 우리가 원하는 모델은 prediction에서 빠르고, training에서는 느려도 괜찮은 모델이다. 하지만, NN모델의 경우 train이 O(1), predict가 O(N)으로 우리가 원하는 상황의 정반대이다.
※ K-Nearest Neighbors
- k개의 가장 가까운 이미지들을 찾고, k개의 이미지들을 두고 다수결로 투표, 가장 많이 나온 것을 택하여 test image가 해당 train image와 가장 유사하다고 판단하는 기법.
- L1(Manhattan) distance : 특징 벡터가 의미 있다면 사용.
- L2(Euclidean) distance : 벡터 요소들의 의미를 모르거나 의미가 없을 때 사용.
- KNN에서 최종 accuracy는 결국 100%
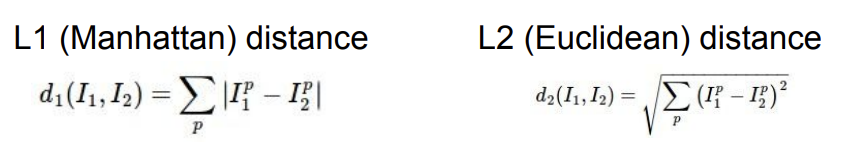
■ hyperparameters란?
- 학습 전에 우리가 선택하는 것(choices about the algorithm that we set rather than learn)
- k=1 설정 지양 : 항상 works perfectly
- train & test 로 데이터를 나누는 것 지양 : 새로운 데이터를 알고리즘이 수행하지 못함.
- train, validation, test 로 데이터를 나누자!!! : train 데이터의 일부를 평가용으로 두고 평가를 진행한 후 새로운 데이터를 가지고 test 해야한다.
- Cross-Validation : validation을 돌아가면서 진행한다. 적은 데이터셋에서는 좋지만, 시간 소모가 심하여 딥러닝에서는 사용 x
★ KNN은 이미지에 사용하지 않는다.
- Very slow
- 이미지에서는 픽셀 간 거리 척도가 그닥 유용한 정보가 아니다.
- Curse of dimensionality
■ Summary
1. Image classification에서 train은 이미지와 라벨의 집합으로, test에서는 라벨을 predict 해야한다.
2. KNN은 nearest training 예시들을 기초로 labels를 predict한다.
3. 거리척도와 K는 하이퍼파라미터이다.
4. validation set은 train 데이터에서 픽하고, test set은 오직 마지막 평가만을 해야한다.
※ Linear Classification
- Just a weighted sum of all the pixel values in the image.

- W: weight, b: bias, X: input Image로 이루어진 선형 함수 작업이다.
- f(X,W) = WX + b
- train을 통해 W에 가중치를 계속 모으고 새로운 데이터로 predict를 진행한다.
- 어떤 모델을 사용할지, W의 값을 얼마나 적절히 학습시키는지가 NN 아키텍쳐를 설계하는 과정이다.

Linear Classifier는 각 클래스를 구분시킬 수 있는 선형 결정 경계가 된다.
복잡한 이미지 판별에서는 선형 식에 한계가 있을 것이다.
■ Hard cases for a linear classifier

1. parity problem : 홀, 짝 분류시 0보다 큰 픽셀의 수가 홀수, 짝수 일때 분별한다. 단순하게 선 하나로 분류가 어렵다.
2. Multimodal problem : 한 클래스가 다양한 공간에 분포하게 되면 linear classifier로 해결하기 어렵다.
728x90'cs231n 정리' 카테고리의 다른 글
cs231n(5강) - CNN (0) 2023.05.30 cs231n 4강 - BackPropogation & Neural Networks (0) 2023.05.23 cs231n 3강 - Loss Function & Optimization (0) 2023.03.23