-
5. 신경망 학습 관련 기술(1)AI 모델(딥러닝 기초)/5. 신경망 학습 관련 기술 2023. 2. 1. 15:50728x90
※ SGD의 단점
우리는 지금까지 확률적 경사 하강법(SGD)를 통해서 최적화를 시도했다. SGD는 기울어진 방향으로 일정 거리만 가도록 만들고 이를 반복적으로 시도하여 최적값을 찾고 accuracy를 개선하는 방식이다.
하지만, 이 SGD의 비효율적인 면이 있어 소개해본다.
■ SGD의 단점 : 비등방성 함수(방향에 따라 성질(기울기)가 달라지는 함수)에 대해서는 탐색 경로가 비효율적이다.
SGD의 원리 자체가 무작정 기울어진 방향으로 일정 거리만 가도록 했기 때문에 기울어진 방향이 본래의 최솟값과 다른 방향을 가리키게 되는 비등방성 함수와 같은 경우에서는 탐색 경로가 지그재그 형태로 상당히 비효율적이다.
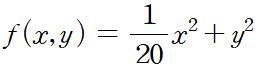
밑바닥 부터 시작하는 딥러닝 교재에서 제공하는 비등방성 함수의 예시이다. 이 함수를 SGD로 최적화 처리를 하려고 하면

<밑바닥부터 시작하는 딥러닝> 194p 이처럼 지그재그 형태의 비효율적인 경로가 설정된다.
※ 모멘텀 기법
SGD 기법의 문제점을 보완한 기법으로 물리적인 요소를 가미한 기법이다.
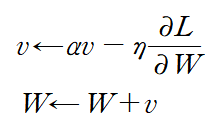
모멘텀 기법의 기본 수식은 위와 같다. W는 갱신할 가중치 매개변수, v는 속도(velocity)를 말한다. 기울기 방향으로 힘을 받아서 물체가 가속된다는 물리 법칙을 나타낸다. 또한 av 항은 물체가 아무런 힘을 받지 않을 때 하강 시키는 역할을 한다. a=0.9로 일반적으로 정의한다.
class Momentum: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): self.v[key] = self.momentum * self.v[key] - self.lr * grads[key] params[key] += self.v[key]Momentum 기법을 코드로 나타내면 위와 같다.
a : self.momentum, v : self.v[key], 학습률 : self.lr, W에 대한 손실함수 : grads[key] 로 표현했다.
update라는 최적화 클래스를 분리하여 만든 기법으로 모듈화 시에 간편하게 사용할 수 있는 장점이 있다.
위 코드를 통해서 Momentum 기법을 사용하여 같은 비등방성 함수를 최적화 처리해보자.
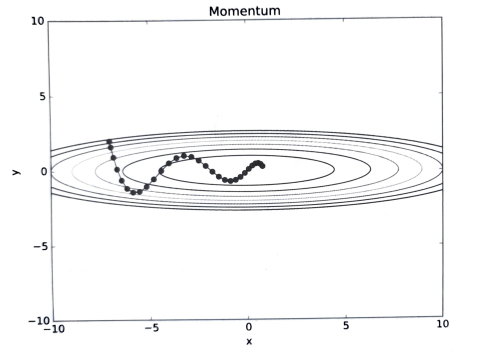
<밑바닥부터 시작하는 딥러닝> 196p SGD에 비해 훨씬 지그재그가 줄어든 것을 확인할 수 있을 것이다. x축의 힘은 아주 작지만 방향은 변하지 않아 한 방향으로 일정하게 가속하기 때문이다. 또한, y축의 힘은 크지만 위아래로 번갈아 받아서 상충하기 때문에 y축 방향의 속도는 안정적이지 않다는 특징이 있다. 물리적인 속도를 도입하여 x축 방향으로 SGD보다 빠르게 다가갈 수 있어 지그재그 움직임이 훨씬 줄어든다.
※ AdaGrad
- 각각의 매개변수에 맞게 맞춤형으로 학습률 값을 낮추는 기법으로 적응적으로 학습률을 조정하면서 학습을 진행한다.

이렇게 수식적으로 정의해 볼 수 있다. h 변수는 기존 기울기 값을 제곱하여 더해주는 값이다. 아래쪽 식에서 W에 매개변수를 갱신할 때 학습률에 1/h^(1/2)를 곱해서 학습률을 조정한다. 매개변수의 원소 중 많이 움직인 원소는 학습률이 낮아지게 되고 학습률 감소가 매개변수의 원소마다 맞춤형으로 다르게 적용된다.
class AdaGrad: def __init__(self, lr=0.01): self.lr = lr self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)이렇게 구현해 볼 수 있다. 여기서 마지막에 1e-7을 더해주어 self.h[key]에 계속 낮아진 학습률이 0이 담겨질 경우에도 0으로 나누는 오류를 막아줄 수 있다.
AdaGrad 기법으로 위의 비등방성 함수를 처리하게 될 경우를 살펴보자.
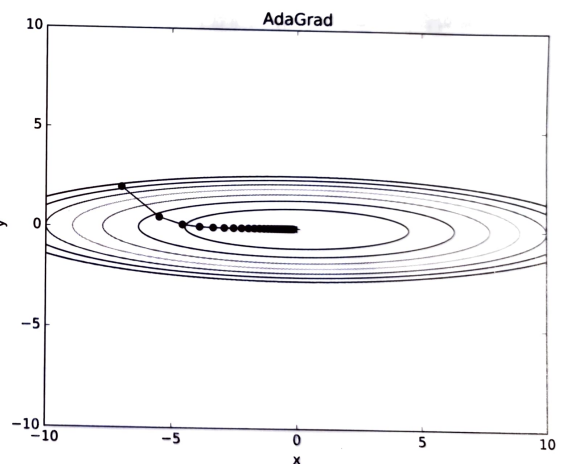
<밑바닥부터 시작하는 딥러닝> 198p 이렇게 Momentum 보다도 더 부드럽게 움직이는 것을 볼 수 있다. y축 방향의 기울기가 커서 처음에는 크게 움직이지만 움직임에 맞게 갱신 정도가 큰 폭으로 작아져서 금방 y축 방향으로 갱신 강도가 약해지면서 지그재그 움직임이 훨씬 줄어든다.
※ Adam
- Momentum과 AdaGrad 기법을 융합한 방식이다. 매개변수 공간을 효율적으로 탐색하고 하이퍼파라미터의 편향 보정 역시 진행된다. Momentum을 사용했으므로 물리적으로 구르는 듯한 느낌을 주지만 편향 보정으로 인해 좌우 흔들림이 상대적으로 적다.
- 일반적으로 Adam은 하이퍼파라미터를 3개 가진다. a : 학습률, b1 : 1차 모멘텀용 계수, b2 : 2차 모멘텀용 계수이다.
(b1 = 0.9, b2 = 0.999) 이 값이면 많은 경우에 좋은 결과를 나타낸다.
class Adam: def __init__(self, lr=0.001, beta1=0.9, beta2=0.999): self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.iter = 0 self.m = None self.v = None def update(self, params, grads): if self.m is None: self.m, self.v = {}, {} for key, val in params.items(): self.m[key] = np.zeros_like(val) self.v[key] = np.zeros_like(val) self.iter += 1 lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for key in params.keys(): self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key]) self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])이렇게 구현이 가능하다.
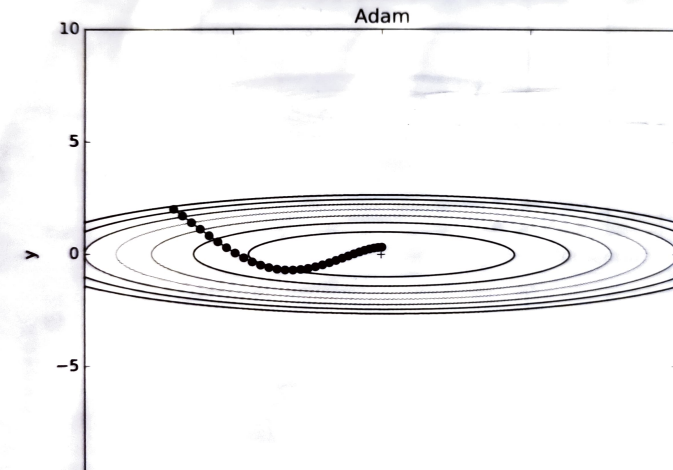
<밑바닥부터 시작하는 딥러닝> 199p 위 비등방성 함수의 최적화 모습이다. 모멘텀처럼 구르는 모습이지만, AdaGrad로 하이퍼파라미터가 적절히 학습률을 감소시키며 편향이 보정되어 흔들림이 적고 부드러운 곡선을 그리는 것을 볼 수 있다.
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정 import numpy as np import matplotlib.pyplot as plt from collections import OrderedDict from common.optimizer import * def f(x, y): return x**2 / 20.0 + y**2 def df(x, y): return x / 10.0, 2.0*y init_pos = (-7.0, 2.0) params = {} params['x'], params['y'] = init_pos[0], init_pos[1] grads = {} grads['x'], grads['y'] = 0, 0 optimizers = OrderedDict() optimizers["SGD"] = SGD(lr=0.95) optimizers["Momentum"] = Momentum(lr=0.1) optimizers["AdaGrad"] = AdaGrad(lr=1.5) optimizers["Adam"] = Adam(lr=0.3) idx = 1 for key in optimizers: optimizer = optimizers[key] x_history = [] y_history = [] params['x'], params['y'] = init_pos[0], init_pos[1] for i in range(30): x_history.append(params['x']) y_history.append(params['y']) grads['x'], grads['y'] = df(params['x'], params['y']) optimizer.update(params, grads) x = np.arange(-10, 10, 0.01) y = np.arange(-5, 5, 0.01) X, Y = np.meshgrid(x, y) Z = f(X, Y) # 외곽선 단순화 mask = Z > 7 Z[mask] = 0 # 그래프 그리기 plt.subplot(2, 2, idx) idx += 1 plt.plot(x_history, y_history, 'o-', color="red") plt.contour(X, Y, Z) plt.ylim(-10, 10) plt.xlim(-10, 10) plt.plot(0, 0, '+') #colorbar() #spring() plt.title(key) plt.xlabel("x") plt.ylabel("y") plt.show()책에서 제공하는 소스코드를 살펴보면서 직접 실행을 시켜보았다. 지금까지 소개한 4가지의 최적화 기법을 모두 나타내어 주었다.

이러한 시각화 상태가 그려졌다. 각각을 확연하게 한 눈에 살펴볼 수 있다. 현재 현업에서는 SGD와 Adam을 주로 사용하지만, 아직까지 모든 문제에서 뛰어난 기법이라는 것은 없다. 학습률과 신경망의 구조(층, 깊이) 등에 따라 결과가 달라진다. SGD보다 다른 기법들이 빠르고 정확하다는 점은 있지만, 각자의 장단점이 있으므로 모든 최적화 기법을 적절히 상황에 맞게 고려하여 사용할 필요가 있다.
728x90'AI 모델(딥러닝 기초) > 5. 신경망 학습 관련 기술' 카테고리의 다른 글
5. 신경망 학습 관련 기술(6) (0) 2023.02.13 5. 신경망 학습 관련 기술(5) (0) 2023.02.13 5. 신경망 학습 관련 기술(4) (0) 2023.02.06 5. 신경망 학습 관련 기술(3) (0) 2023.02.04 5. 신경망 학습 관련 기술(2) (0) 2023.02.03