-
5. 신경망 학습 관련 기술(5)AI 모델(딥러닝 기초)/5. 신경망 학습 관련 기술 2023. 2. 13. 15:05728x90
※ Dropout 기법
overfitting 개선을 위한 방법으로 신경망 모델이 복잡해져 가중치 감소만으로 대응이 어려울 때 사용한다.
- 뉴런을 임의로 삭제하면서 학습하는 방법(자연스러운 가중치 감소 방식)
- 훈련 시에 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택하고, test 때 모든 뉴런에 신호를 전달한다. test 때는 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱하여 출력한다.
class Dropout: def __init__(self, dropout_ratio=0.5): self.dropout_ratio = dropout_ratio self.mask = None def forward(self, x, train_flg=True): if train_flg: self.mask = np.random.rand(*x.shape) > self.dropout_ratio return x * self.mask else: return x * (1.0 - self.dropout_ratio) def backward(self, dout): return dout * self.maskself.mask에 x와 형상이 같은 배열을 무작위로 생성하고, dropout_ratio 보다 큰 경우 원소만 True로 설정한다. train_flag=True를 통해서 순전파 시에 self.mask에 x를 곱하여 그대로 흘려준다. 역전파에서는 ReLU와 같은 동작을 한다.
순전파 때 신호를 통과시키는 뉴런은 역전파 때도 신호를 그대로 통과시키고, 순전파 때 통과시키지 않은 뉴런은 역전파 때도 신호를 차단한다.
# coding: utf-8 import os import sys sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정 import numpy as np import matplotlib.pyplot as plt from dataset.mnist import load_mnist from common.multi_layer_net_extend import MultiLayerNetExtend from common.trainer import Trainer (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True) # 오버피팅을 재현하기 위해 학습 데이터 수를 줄임 x_train = x_train[:300] t_train = t_train[:300] # 드롭아웃 사용 유무와 비울 설정 ======================== use_dropout = True # 드롭아웃을 쓰지 않을 때는 False dropout_ratio = 0.2 # ==================================================== network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio) trainer = Trainer(network, x_train, t_train, x_test, t_test, epochs=301, mini_batch_size=100, optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True) trainer.train() train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list # 그래프 그리기========== markers = {'train': 'o', 'test': 's'} x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, marker='o', label='train', markevery=10) plt.plot(x, test_acc_list, marker='s', label='test', markevery=10) plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()MNIST 데이터셋을 활용한 301개의 epoch을 조사해보았다. dropout 기법을 사용하여 구현하여 적용한다.
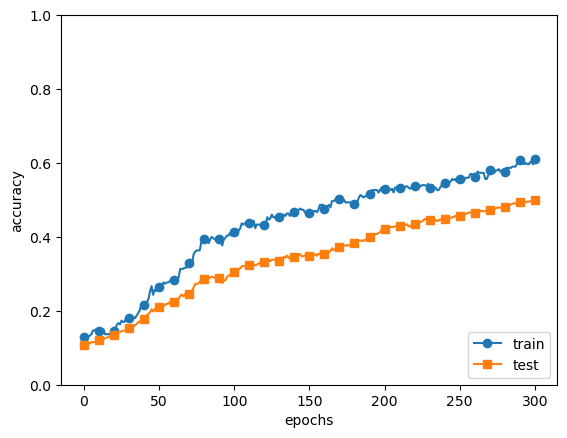
결과는 위와 같이 나오면서 301개의 epoch 들이 dropout이 적용되어 적절한 값의 차이를 가지며 overfitting을 개선할 수 있다. 또한, 훈련 데이터 정확도가 100%에 도달하는 일도 개선되어 표현력을 높이면서 오버피팅도 억제하는 효과를 불러올 수 있었다.
728x90'AI 모델(딥러닝 기초) > 5. 신경망 학습 관련 기술' 카테고리의 다른 글
5. 신경망 학습 관련 기술(6) (0) 2023.02.13 5. 신경망 학습 관련 기술(4) (0) 2023.02.06 5. 신경망 학습 관련 기술(3) (0) 2023.02.04 5. 신경망 학습 관련 기술(2) (0) 2023.02.03 5. 신경망 학습 관련 기술(1) (0) 2023.02.01